



Teams looking to build machine learning applications that are scalable, easy to maintain, and highly efficient can’t omit the step of building a machine learning architecture. Developing a solid ML architecture with a well-thought-out data pipeline results in better performance from machine learning algorithms, less time spent on experimentation, development, deployment, and maintenance, and less debugging.
A well-designed architecture also ensures the integrity and security of the machine learning infrastructure, allowing for continuous improvement.
Keep reading to get a primer on machine learning architecture and see how it enables teams to build strong, efficient, and scalable ML systems capable of meeting the demands of modern, data-driven companies.
What is Machine Learning (ML) Architecture?
Machine learning architecture is the structure and organisation of the many components and processes that are part of a machine learning system. It defines how you process data, train and evaluate ML models, and generate predictions. An architecture is basically a model for creating an ML system.
The architecture of a machine learning application will depend on the unique use case and system requirements.
Here’s an example of a visualized ML architecture:
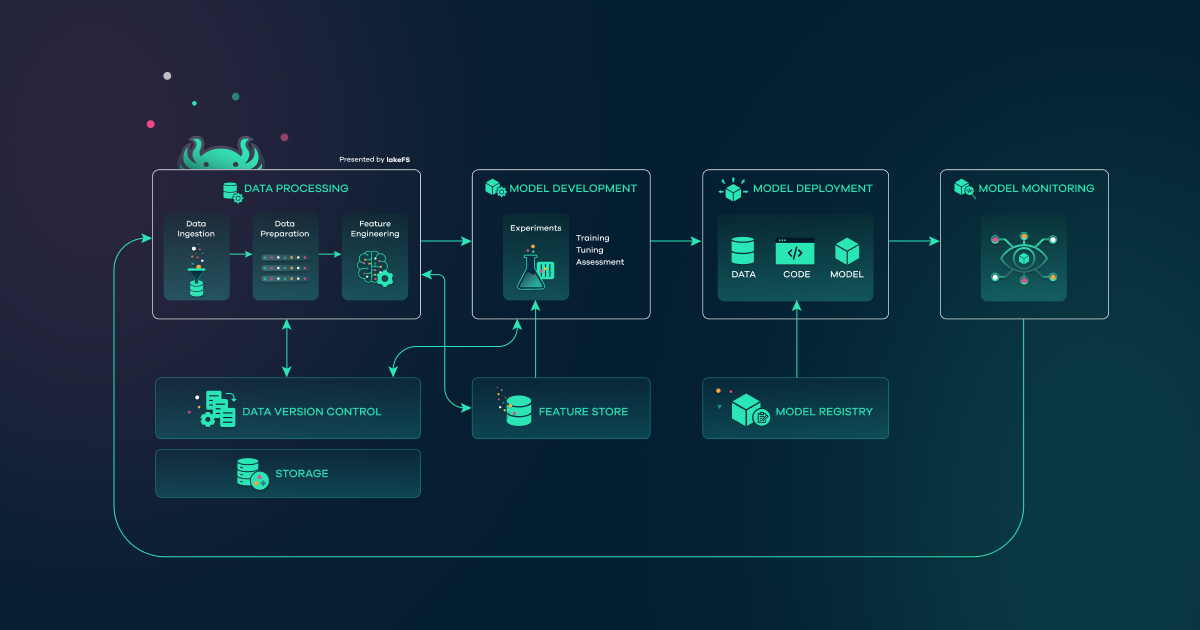
Example ML architecture diagram. Source: lakeFS
Machine Learning Architecture Components
Data Ingestion
Data ingestion is the process of acquiring and processing data for use in machine learning models. The quality and quantity of data ingested during data collection have a major impact on the accuracy and efficacy of the models, making it a vital stage in the machine learning process.
Here are a few common data ingestion steps:
- Data collection – acquiring information from a variety of sources, such as data lakes, databases, APIs, sensors, or external datasets, representing the real-world circumstances that the model will be used to forecast or categorize.
- Data cleansing – errors, inconsistencies, or missing values in the gathered data must be discovered and repaired before ingestion to maintain high data quality.
- Data transformation – turning raw data into a format appropriate for machine learning algorithms with the goal of increasing performance. This is often important in natural language processing applications.
- Data integration – merging data from several sources into a single dataset suitable for machine learning.
- Data sampling – picking a representative selection of data from an ingested collection to shrink the dataset and guarantee that the model is trained on a balanced dataset with both positive and negative instances.
- Data splitting – partitioning an ingested dataset into different training, validation, and testing sets to assess the model’s performance on fresh, previously unknown data and to avoid overfitting.
Data intake for machine learning is a vital phase in the machine learning pipeline that must take into account data quality, data preparation, and feature engineering. To increase the accuracy and efficacy of the generated models, you need to make sure that the ingested dataset is reflective of the real-world scenarios that the model will be used to predict or categorize and that the dataset is adequately processed and cleaned.
Common types of data ingestion include:
- Batch data ingestion – the process of ingesting data in large batches, where data is gathered from various sources and put into the target system in predetermined batches. A good pick for processing vast amounts of data that do not require real-time analysis.
- Real-time data ingestion – this is the process of consuming data as soon as it becomes accessible, with data gathered from many sources and put into the target system in real time. It works well for processing data that requires quick action or analysis, such as fraud detection or predictive production.
- Ingestion of Change Data Capture (CDC) – the process of recording real-time changes to data. CDC ingestion works well for processing continually updated data, such as social media feeds or stock prices.
- Streaming data ingestion – ingesting data in real-time from streaming sources such as sensors or IoT devices. It’s great for processing data that calls for a quick response, such as traffic monitoring or weather forecasting.
Common tools used for data ingestion are Apache Kafka, Apache Spark, Amazon S3, Apache Nifi, Google Cloud Dataflow, Apache Flume, Talend Open Studio, and StreamSets.
Data Storage
Selecting the optimum storage for all phases of a machine learning project is more important than you expect. What usually happens is that teams produce numerous dataset versions and experiment with various model designs. When a model is promoted to production, it must make predictions on fresh data efficiently. The ultimate aim is to have a well-trained model operating in production that adds AI to an application.
Whatever model you develop, once in production, it must be accessible, scalable, and robust, just like any other service you deploy as part of your application.
To address these requirements, the storage solution you pick for your ML project needs to be:
- Scalable – the storage should be able to accommodate rising amounts of storage without requiring substantial adjustments. As capacity and throughput needs grow, scalable storage can continue to perform optimally.
- Available – this isn’t only about the operational system’s capacity to complete a task but also the amount of time it takes for a resource to start processing an individual request (excessive wait times cause a system to become unavailable).
- Secure – storage access must be validated and authorized, while data should also be safe at rest and have encryption options. The ability to lock data, version data, and establish retention policies are key security issues.
- Performant – your storage needs to be optimized for high throughput and minimal latency. This is critical during model training since better performance equals faster completion of experiments. Performance matters a lot to teams that use GPUs – if a storage solution cannot transmit data at a pace that is equal to or greater than the processing rate of a GPU, the system will waste GPU cycles.
Common storage environments for ML projects are:
- Local file storage – good choice for PoC phase, but comes with limited storage capacity and is not appropriate for big datasets. A local file system isn’t accessible, dependable, or scalable since there is no replication or autoscaling. They are only as safe as the system they are running on.
- Network-attached storage (NAS) – while this solution is secure, NAS devices experience scalability issues when facing massive volumes of data due to the underlying storage structure’s hierarchy and pathing.
- Storage-area networks (SAN) – a SAN is more difficult to set up than a NAS, making it also expensive and time-consuming to maintain. This storage type is still a file-based system, so all the scalability limitations apply to it as well.
- Distributed file systems (DFS) – it distributes data over numerous servers or containers, enabling users to view and edit files as if they were on a single, centralized file system. Google File System (GFS), Hadoop Distributed File System (HDFS), Amazon Elastic File System (EFS), and Azure Files are some examples. Still, you’re again looking at scalability issues when working with a huge number of files.
- Object storage – here we’re talking about solutions like Amazon S3, Azure Blob Storage, and Google Cloud Storage. The S3 API is the de facto standard for developers to interface with storage and the cloud, and many companies provide S3-compatible storage for public, private, edge, and co-located settings. Such solutions provide near-infinite scaling to petabytes, making them ideal for storing datasets and maintaining huge models.
Data Version Control
Data versioning is a component used over storage in a machine learning architecture. Its advantages are vast and impact all stages of the ML process, from CI/CD for data ingestion and data pre-processing, to efficient and fully reproducible experimentation and fast recovery from issues in production. All those advantages come while keeping the storage cost effective and clean, avoiding data swamp.
Different versions of datasets used in machine learning algorithms provide deeper knowledge into how the data has grown over time, as well as what data has been added or removed from previous versions.
Data version control allows developers to examine prior versions and see what changes have been made. Versioning data, models, and infrastructure allows full reproducibility of any version of a model you have ever tried or used.
Model Assessment
Model assessment or evaluation is the process of assessing a model’s performance via metrics-driven analysis. It may be done in two ways:
- Offline – during experimentation or continual retraining, the model is assessed after training.
- Online – as part of the continuous model monitoring, the model is reviewed in production.
The metrics used in the study are chosen based on the data, methodology, and use case:
- In supervised learning, the metrics are classified into classification (accuracy, precision, recall, and f1-score) and regression (mean absolute error (MAE) and root mean squared errors (RMSE)).
- In unsupervised learning, metrics characterize the cohesion, separation, confidence, and error in the output. The silhouette measure, for example, is used in clustering to determine how similar a data point is to its own cluster in comparison to its resemblance to other clusters.
Model assessment metrics are expanded during experimentation with visualizations and manual inspection of data points for both learning techniques.
In addition to technical measures and analysis, teams should develop and report on business KPIs, such as additional revenue and cost savings, to understand the implications of bringing the model into production.
ML model evaluation is key for essential applications that use real-time inference since an erroneous or insufficient model assessment can be fatal for both user experience and revenue.
It’s important that model assessment occurs throughout both experimentation and production. To facilitate model evaluation during experimentation, you need to remove a test set and a holdout.
For evaluating an ML model in production, teams need to implement a model monitoring method that takes recent production data and model predictions and analyzes the ML model performance.
Model Deployment
Model deployment refers to the integration of a trained machine-learning model into a real-world system or application to automatically create predictions or execute certain tasks.
Consider a healthcare business creating a model to predict the likelihood of readmission for patients who suffer from chronic diseases. Model implementation would entail integrating the trained model into the company’s existing electronic health record system.
Once deployed, the model can evaluate patient data in real time, providing healthcare workers with insights to help them identify high-risk patients and take proactive actions to reduce patient readmissions.
To guarantee that the model functions reliably in the organization’s production environment, data scientists, IT teams, software developers, and business experts must collaborate. This is a significant challenge.
Model Monitoring
The monitoring stage of the data science lifecycle happens once a model has been successfully deployed. It guarantees that the model is operational and that its forecasts are accurate.
After deployment, a variety of issues may arise:
- Resources may be insufficient
- The data feed may be improperly linked
- Users may not be using ML apps appropriately
The best strategy to monitor a model is to examine its performance in its deployed context on a regular basis. This should be an automated procedure with tools that track metrics and inform you if their accuracy, precision, or F-score changes.
Every model that is implemented has the potential to deteriorate over time owing to factors such as variability in delivered data, data integrity changes, inaccurate data, or shift of the leading concept.
Using an enterprise data science platform, you can automatically monitor for each of these issues using a range of monitoring tools and warn your data science team as soon as a deviation in the model is found.
Model Training
A training model is a dataset used to train a machine learning algorithm, which is made up of sample output data and the related sets of input data that impact the outcome. You can use the training model to run the input data through the algorithm to compare the processed output to the sample output.
This is called model fitting. The precision of the model is dependent on the correctness of the training or validation datasets.
When the training data comprises both the input and output values, supervised learning is possible. A supervisory signal is any set of data that includes the inputs and the intended result. When the inputs are fed into the model, the training is done based on the divergence of the processed output from the recorded result.
Unsupervised learning entails identifying patterns in data. Following that, further data is utilized to fit patterns or clusters. This is an iterative process that improves accuracy based on correlation to predicted patterns or clusters. This method has no reference output dataset.
Model Retraining
Model retraining (continuous training) is the capacity of MLOps to automatically and constantly retrain a machine learning model on a schedule or a trigger triggered by an event.
Retraining is essential for ensuring that a machine learning model is always offering the most up-to-date predictions, while also reducing manual interventions and optimizing for monitoring and dependability. It is critical that you specify what makes an output the most accurate for your business use case and how to assess this accuracy for a successful retraining process.
The data scientists who created the model often need to perform a complete observability and explainability study that informs offline measurements, technical and business online metrics, baseline behavior, projected performance, and the impact of deterioration.
Depending on your data strategy, you can use:
- Offline learning – the most common method where each retraining uses all available data or the most recent period of data with the same ideal duration (for example, a year).
- Online learning – a good match for systems that use real-time streaming data. Rather than retraining on previously viewed samples, the system is retrained by progressively forwarding only fresh data instances.
Types of Machine Learning Data Training
Supervised Learning
The training data in supervised learning is a mathematical model that includes both inputs and intended outputs. Each matching input has a corresponding output (supervisory signal). The system can establish the relationship between the input and output using the available training matrix and apply it to additional inputs post-training to obtain the related output.
Based on the output criteria, supervised learning can be expanded into classification and regression analysis. When the outputs are confined in nature and limited to a set of values, classification analysis is given. Regression analysis, on the other hand, specifies a numerical range of values for the outcome.
Various algorithms are used in supervised learning, including:
- Linear regression
- Naive Bayes
- Neural networks
- Convolutional neural networks
- Logistic regression
- Support vector machines (SVM)
- K-nearest neighbor
- Random forest
Unsupervised Learning
Unsupervised learning is a sort of machine learning in artificial intelligence that learns from data without human supervision. Unsupervised machine learning models, in contrast to supervised learning, are given unlabeled data and allowed to identify patterns and insights without any explicit direction or instruction.
Unsupervised learning, as the name implies, employs self-learning algorithms that learn without the need for labels or prior training. Instead, the model is given raw, unlabeled data and is expected to deduce its own rules and arrange the information based on similarities, differences, and patterns without being given explicit instructions on how to interact with each piece of data.
Common unsupervised learning algorithms are:
- K-Means clustering
- Cluster analysis
- Anomaly detection
- Apriori algorithm
- Principal component analysis
Reinforcement Learning
Reinforcement learning is a machine learning training strategy that rewards positive behaviors while penalizing undesirable ones. A reinforcement learning agent (the entity being taught) can sense and understand its surroundings, perform actions, and learn via trial and error.
Positive values are allocated to desired acts to encourage the agent to employ them, while negative values are assigned to undesirable behaviours to discourage them. This instructs the agent to seek the long-term and greatest overall benefits in order to reach the best result.
Architecting the Machine Learning Process
Data Acquisition and Storage
Data acquisition is the process of collecting data from relevant sources before it is stored, cleansed, preprocessed, and used for future procedures. It is the process of gathering important business information, translating it into the appropriate business form, and loading it into the specified system.
A data scientist spends the majority of their time looking for, cleaning, and processing data. This is essential since the best machine learning algorithms cannot work correctly in the absence of sufficient data and data cleansing. Otherwise, you risk the “garbage in, garbage out” scenario.
Data Processing
Data processing is transferring data from one format to another to make it more relevant and informative. This entire process may be automated using machine learning algorithms, mathematical modeling, and statistical expertise.
Depending on the work at hand and the machine’s requirements, the output of this process can take any shape, such as graphs, films, charts, tables, photos, and so on. Data preprocessing is an important phase in the machine learning (ML) pipeline since it prepares the data for use in the development and training of ML models.
Data processing improves model performance by cleaning and translating data into a format suitable for modeling. It transforms data into a format that better depicts the underlying connections and patterns in the data, making it easier for the ML model to learn from the data.
However, data processing can become time-consuming, especially when dealing with large and complicated datasets. Since it includes changing and cleaning data, data processing may result in the loss of vital data or the introduction of new issues.
Note: Consider adding tools that allow you to introduce version control and reproducibility in your ML project.
Data Modeling
Data modeling is the act of visualizing the entire information system or its sections to communicate links between data points and structures. The purpose is to demonstrate:
- The many forms of data used and stored inside the system
- Relationships between different data types
- Various ways the data may be categorized and arranged
- Data formats and features
Data models are designed to meet the demands of businesses. Rules and requirements are created in advance based on feedback from business stakeholders so that they may be integrated into the design of a new system or altered in an existing one’s iteration. A data model is similar to a roadmap, an architect’s plan, or any formal layout that allows for a more in-depth knowledge of what is being built.
Standardized schemas and formal methodologies are used in data modeling. This provides a standardized, consistent, and predictable method of defining and managing data resources within a business.
Execution
As machine learning systems have grown more complicated over time, their execution methodologies have changed to match the needs of current machine learning workflows. Data parallel execution, task parallel execution, and parameter servers are three common execution methods in the world of ML.
- Data parallel execution – often used in deep neural network training and deep learning architecture. The training data is partitioned among many processing units, and each unit trains a copy of the model on its own subset of the data. Each processing unit’s outputs are then merged to update the model parameters. This method enables efficient processing of huge datasets and scales well to massive clusters.
- Task parallel execution – a mechanism for parallelizing the execution of individual tasks in a machine learning process. You can use it to parallelize the processing of individual data points in a data preparation pipeline. This method can increase the efficiency of the data pretreatment pipeline while decreasing total training time.
- Parameter servers – a typical execution technique for distributed machine learning systems is parameter servers. The model parameters are kept on a centralized server in this technique, while the processing units handle the computation of model updates. Each processing unit receives a subset of the training data and computes model parameter updates based on its own subset. The modifications are subsequently transmitted to the parameter server, which aggregates them and updates the model parameters.
Deployment
Model deployment is a critical step in the ML architecture. If you cannot consistently obtain practical insights from your model, the model’s effectiveness is severely constrained.
Here’s an example model deployment flow assuming the use of machine learning platforms:
- First, the model must be transferred into its deployed environment, where it will have access to the hardware resources it requires as well as the data source from which it will pull data.
- Next, you need to integrate the model into a process, making it accessible from an end user’s laptop via an API or integrating it with software that the end user is already using.
- Finally, the model’s users must be instructed on how to activate it, access its data, and evaluate its results.
User Interface
The ability to show and explain their models to non-technical people is a big barrier for data scientists, data analysts, and machine learning engineers. This calls for other skills, such as frontend development (especially relevant to user interface development), backend development, and, in some cases, DevOps.
These tasks may turn out to be time-consuming, but you can use libraries and packages to make your life easier and speed up the process.
Iteration and Feedback
Teams often get input from the model’s surroundings in machine learning systems, which is subsequently fed back into the system. This can take several forms, including using the model’s output to train newer versions of the model or leveraging user input on the model’s judgments to improve the model.
While many feedback loops are beneficial and will increase your model’s performance over time, certain loops can actively damage the machine learning system’s performance over time. This is why creating useful feedback loops is a key part of designing a machine learning system, and it must be done carefully to guarantee that your system is sustainable.
How To Set Up Your Own ML Architecture?
A well-designed architecture can have a considerable influence on the model’s performance, training speed, and generalizability.
Here’s an example of steps teams take when developing their machine learning architecture:
- Set the problem statement – what is the problem you’re trying to solve? Is it a classification, regression, or some other type of task? Understanding your challenge will help you select the best model type and architecture.
- Pick the best frameworks – machine learning frameworks provide varying degrees of flexibility and usability. Select one that corresponds to your experience and project needs. TensorFlow, PyTorch, and scikit-learn are popular choices.
- Choose model components – Each layer of your model serves a distinct purpose. Consider the following aspects:
- Preprocessing and Input Layers
- Neuron Configuration and Hidden Layers
- Activation Functions
- Output Layer
- Connect the layers and build the flow – Determine how data travels from the input layer to the output layer via hidden layers. This progression of layers creates the architecture’s structure. To reduce overfitting and increase model generalization, use techniques like dropout, batch normalization, and L2 regularization.
- Visualize the architecture – you can use visual tools such as diagrams and flowcharts. This helps to identify any issues with the overall design.
Conclusion
To create an architecture that properly processes data and fulfills your goal, you must first have a thorough grasp of your problem, the correct tools, and a creative approach. Consider the components, tools, and best practices we listed above, and you’ll be on your way to building a solid machine learning architecture for your project.
If you want to stay on top of ML technologies, check out this article: What Is LangChain and How Is It Used In ML Architectures?





