

Dagster is a cloud-native data pipeline orchestration tool for the whole development lifecycle, with integrated lineage and observability, a declarative programming model, and best-in-class testability. It is designed for developing and maintaining data assets. With Dagster, you declare—as Python functions—the data assets that you want to build. Dagster then helps you run your functions at the right time and keeps your assets up-to-date.
Dagster offers several key components to help users build and run their data pipelines, including Assets, Ops, and Jobs. Orchestration is a fundamental component in every data operation, as it helps manage the complexity that comes with orchestrating data pipelines that are built of hundreds (or thousands) of steps, and depend on one another in non-trivial ways.
Even with the best orchestrators, some steps in the pipeline may fail due to bugs in the function code, or changes to the nature of the data. In other cases steps don’t fail, they just produce bad data that then cascades to the next steps of the pipeline. This creates a challenge in troubleshooting a data issue once you become aware of it. When an operation out of hundreds of Ops fails/ produces bad data, it is incredibly difficult to understand, after the fact, what caused the failure.
In this article I’ll demonstrate how to use lakeFS with Dagster orchestrated pipelines, to quickly analyze and troubleshoot failed/erroneous pipelines, improving data reliability and reducing time to resolution. lakeFS will provide the ability to define CI/CD for the data that is managed and produced by the data pipelines. This concept guarantees the robustness and quality of the data.
How is Dagster used with lakeFS?
The goal of using Dagster with lakeFS is to create an isolated environment of the data to run production pipelines, in a way that ensures only quality data is exposed to production. Instead of running your data pipelines directly on production data, we create an isolation that will allow us to safely run production pipelines, and in case of failure/quality issues, troubleshoot them directly.
There are 2 options to run your Dagster pipelines in isolation by using lakeFS:
Option 1: Run Job in Isolation
With this approach, we will create a branch out of our production environment (lakeFS this is a zero copy operation that takes a few milliseconds) and run the Dagster job on that branch. Once completed, we will merge the final output of the job back into production:
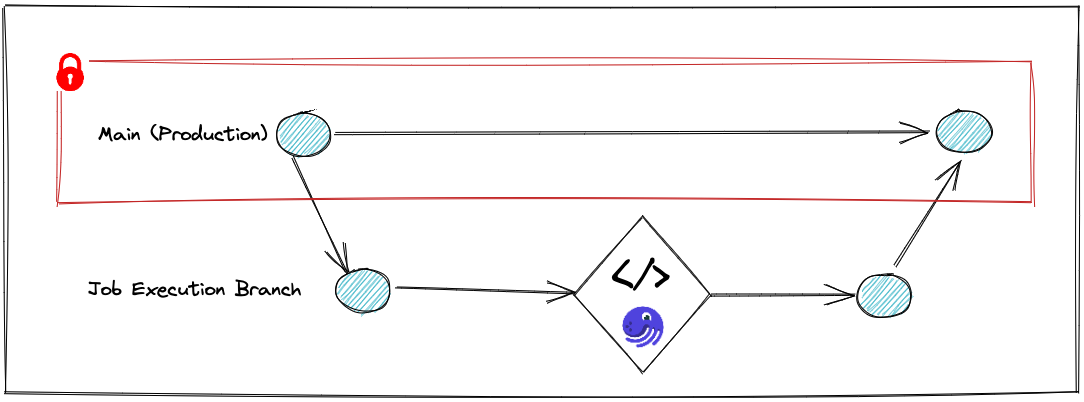
This approach might be the best approach for a quick win:
| Pros | Cons |
| Extremely quick setup for any existing Dagster pipeline | No Commit history within Ops of a Dagster job |
| Isolated “staging” environment. Data is promoted atomically only once a job ends | |
| Only promote high-quality data to production;, users are not aware of “in-process” data | |
| Easily rollback the data assets state in case of error to before the job started |
Option 2: Execute Git actions within Ops
With this approach, we will not only run the pipeline on an isolated branch (similar to the previous option). In addition, we will run Git actions INSIDE the Ops. This means we will have a commit history of changes across all Ops executed within the pipeline:
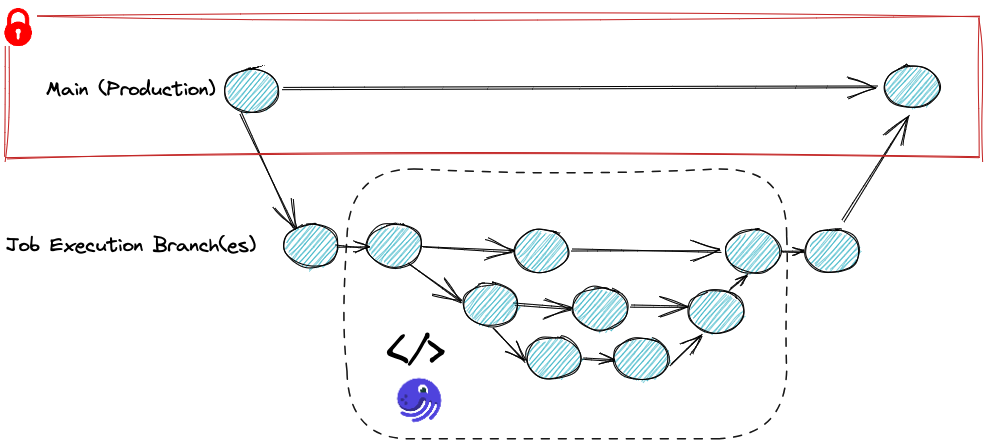
This approach requires more code; However, it provides more value on top of the previous one:
| Pros | Cons |
| Complete in-context copy of the data for every step executed within a job | Requires integrating the git actions within the Ops execution. |
| Isolated “staging” environment. Data is promoted automatically only once a job ends | |
| Only promote high quality data to production;, users are not aware of “in-process” data | |
| Easily rollback the data assets state in case of error to before the job started |
Setup: How to get started
1. Run a lakeFS Server
To demonstrate this, you will need a lakeFS server running.
You can either use a lakeFS Cloud, which is an isolated lakeFS environment (using our storage but you can also use your own storage). Or, spin up a local lakeFS environment.
2. Reference notebook example
We provide this sample, which can be used to run the Dagster jobs with lakeFS against your lakeFS server.
First, clone:
git clone https://github.com/treeverse/lakeFS-samples && cd lakeFS-samples/01_standalone_examples/dagster-integrationThen, run Docker container:
docker compose upOnce you run the container, access your notebook UI by going to the address http://127.0.0.1:8888/ in your browser:
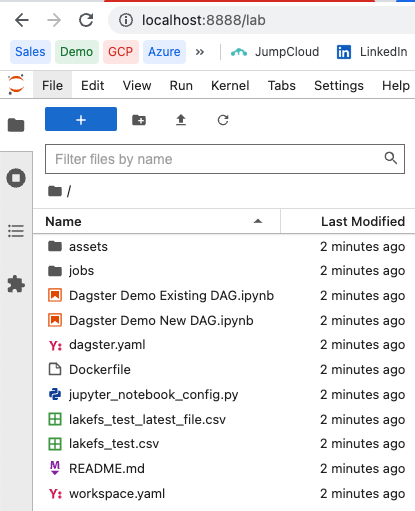
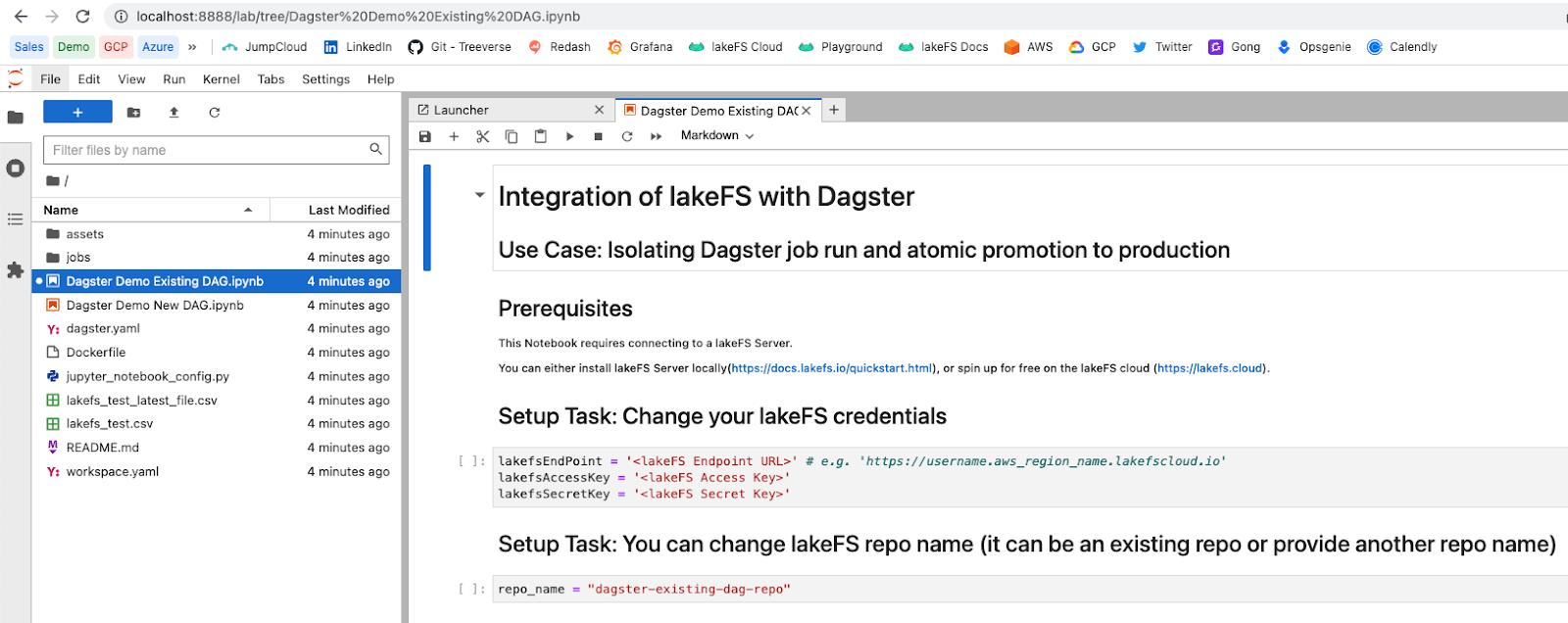
3. Modify the notebooks
The two examples we will use are “Dagster Demo Existing DAG” (option 1) and “Dagster Demo New DAG” (option 2).
Click on the file to review and edit it:
To run this example, we will need to input your lakeFS server details (the one created here).
Specifically,
- Enter lakeFS endpoint and credentials
lakefsEndPoint = '<lakeFS Endpoint URL>' # e.g. 'https://username.aws_region_name.lakefscloud.io'
lakefsAccessKey = '<lakeFS Access Key>'
lakefsSecretKey = '<lakeFS Secret Key>'If you don’t have lakeFS access and secret keys, login to lakeFS and click on Administration -> Create Access Key
A new key will be generated:
As instructed, copy the Secret Access Key and store it somewhere safe. You will not be able to access it again (but you will be able to create new ones).
- Since we are creating a repository in the demo, we will need to change the storage namespace to point to a unique path. If you are using your own bucket, insert the path to your bucket. If you are using our bucket in lakeFS Cloud, you will want to create a repository in a subdirectory of the sample repository that was automatically created for you.
For example, if you login to your lakeFS Cloud and see:

Add a subdirectory to the existing path (in this case, s3://lakefs-sample-us-east-1-production/AROA5OU4KHZHHFCX4PTOM:028298a734a7a198ccd5126ebb31d7f1240faa6b64c8fcd6c4c3502fd64b6645/). i.e. insert:
storageNamespace = 's3://lakefs-sample-us-east-1-production/AROA5OU4KHZHHFCX4PTOM:028298a734a7a198ccd5126ebb31d7f1240faa6b64c8fcd6c4c3502fd64b6645/dag1/' # e.g. "s3://username-lakefs-cloud/"4. Run notebooks
You can now run the notebooks step by step and view the changes in your lakeFS Server.
Notice:
- The Setup tasks will start Dagster;, configure the job as well as install a lakeFS Python Client.
- You can click on any links in the output log and it will take you to applicable branch/commit/data file in lakeFS
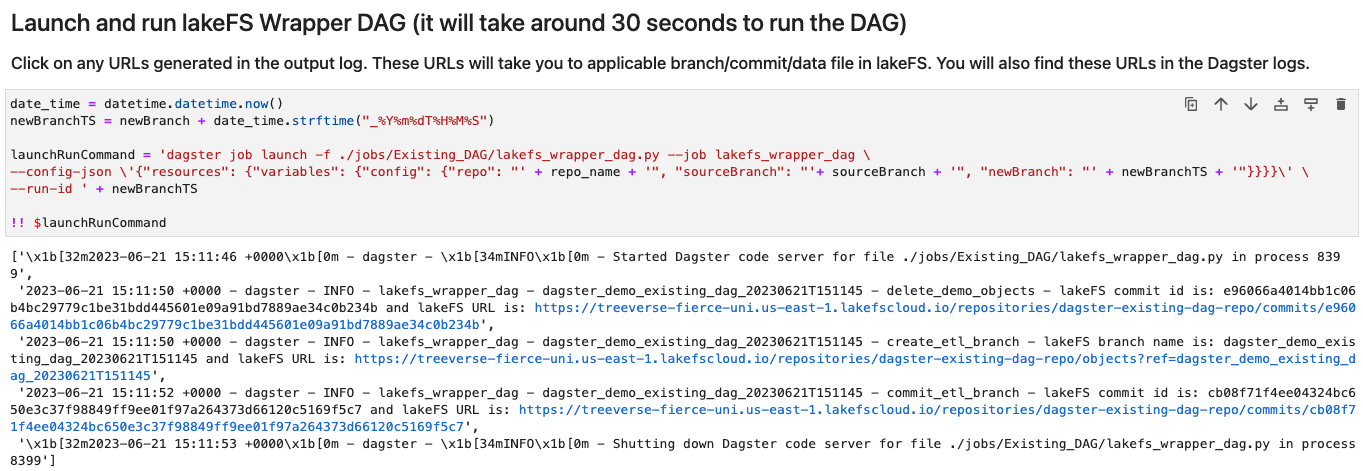
e.g. if you click on any link for a commit, you will see lakeFS UI like this:
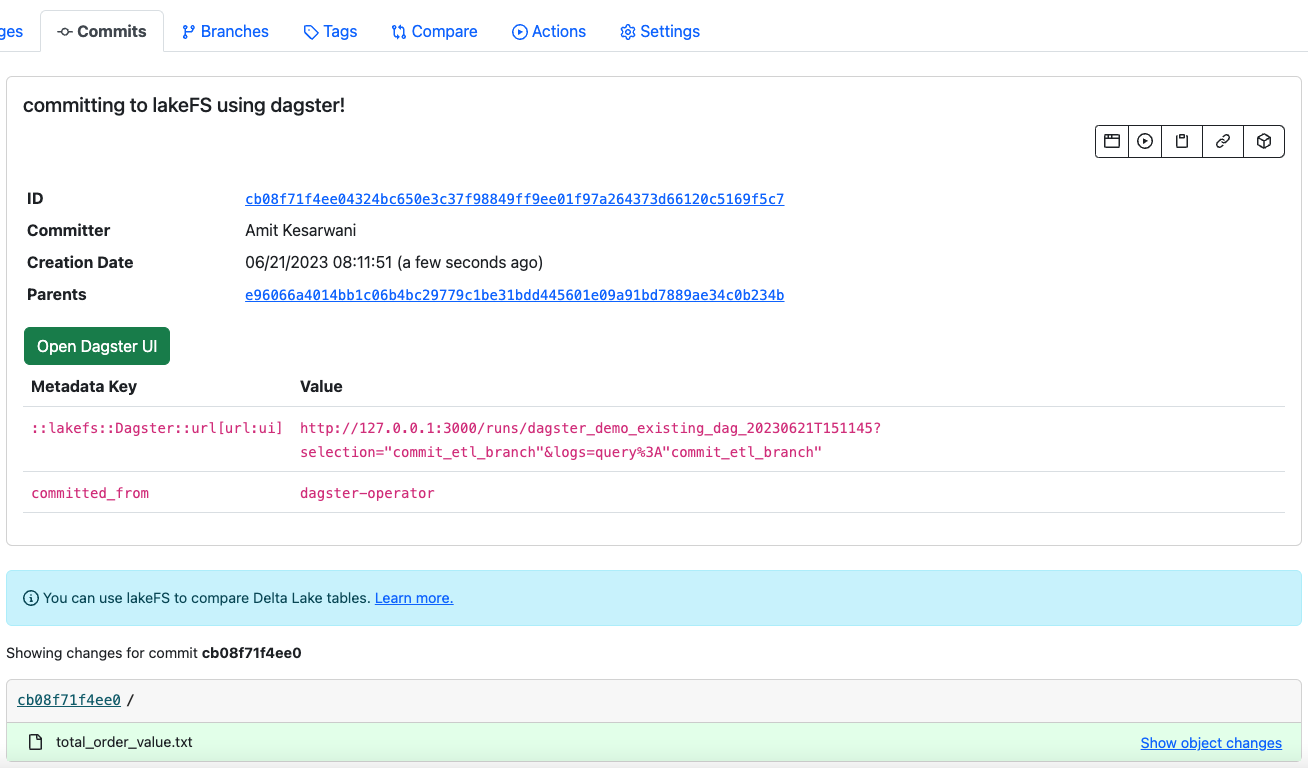
You can click on the “Open Dagster UI” button in lakeFS UI and it will take you to applicable operation in Dagster which created a particular commit:
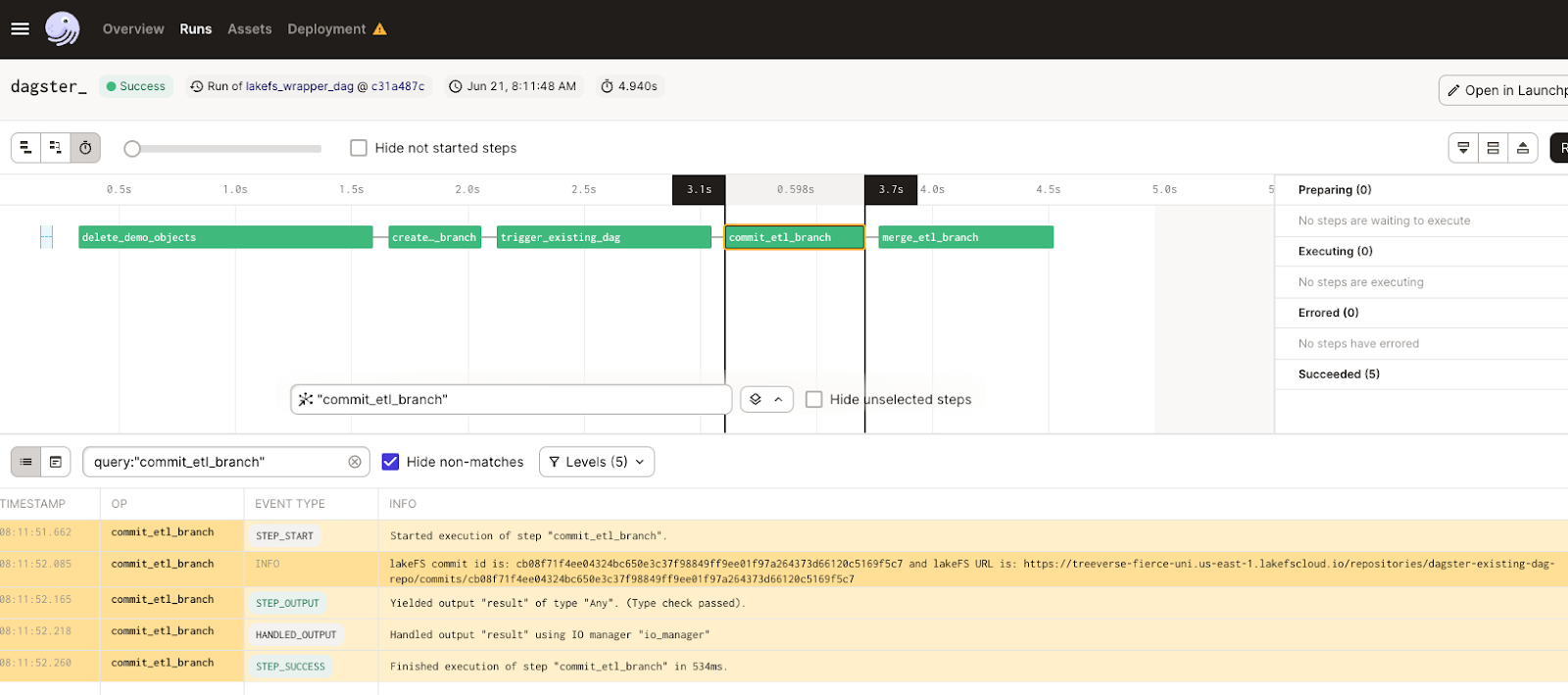
- If you go back to your notebook and run the next cell then you can click on the link to go to Dagster UI when prompted. For example, Click here:
To get access to the graphical representation of the Dagster graph:

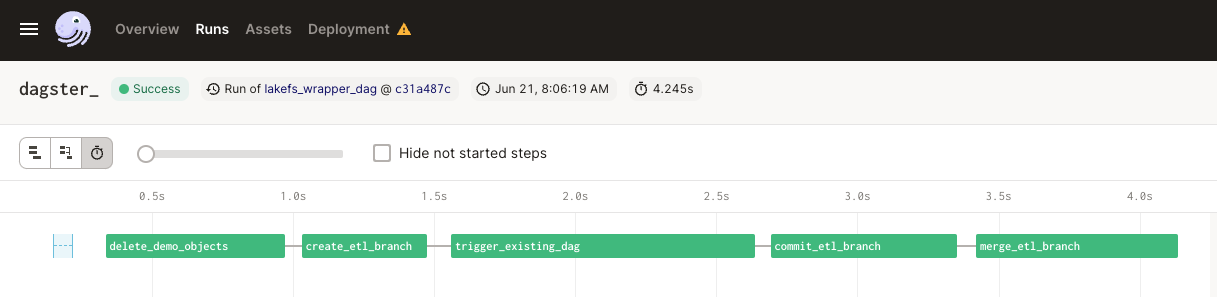
- As the job runs, don’t forget to switch over to lakeFS and observe the branches merges and commits taking place.
5. Troubleshooting pipelines
The second notebook (“Dagster Demo New DAG”) runs the same job twice. Once with valid input, and the second with invalid input.
When you run the job a second time against the bad input data (“lakefs_test_latest_file.csv”), the task will fail and you will get following “Exception”:

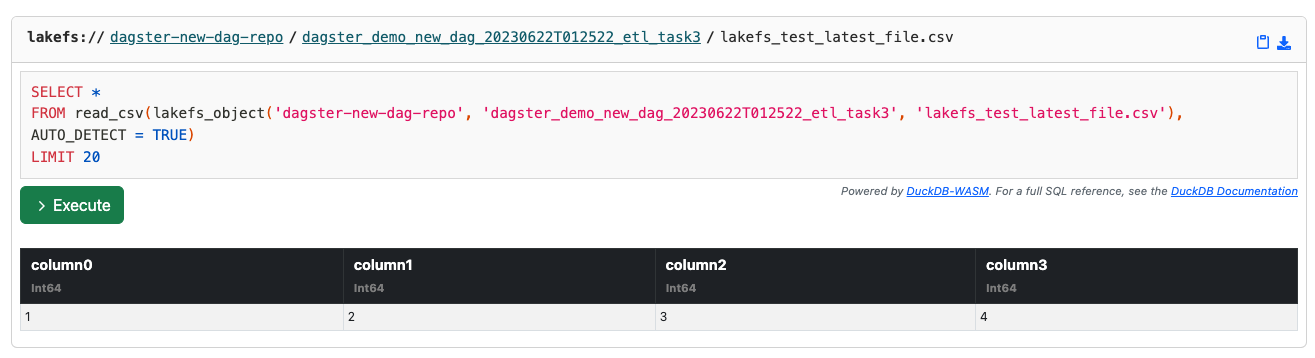
This exception happens because column “_c4” (or 5th column) is missing in the latest file.
You will also see in Dagster UI that “etl_task3” operation failed:

Now, with lakeFS, we can see the exact data at the point of the failure in that specific operation.
- Get the snapshot of the data at the time of the failure
In the output log, you will see the logged message for “create_etl_task3_branch” operation (which is the operation just before failed “etl_task3” operation) with a link to the branch at the time of the failure:

Click on this link to open lakeFS server on that branch:
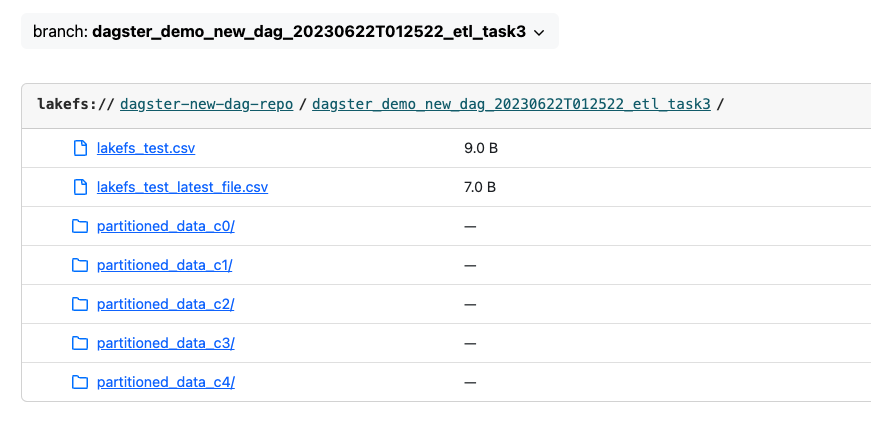
You can click on the file (lakefs_test_latest_file.csv) and indeed, you can see the file is missing the 5th column:
Summary
We went over two scenarios: running an existing job in isolation and creating a new job with Git-like actions. In both cases, you achieve:
- Isolated staging environments with no copy
- Promote only quality data to production: Atomically promote the data only once the job finishes execution successfully.
- In case bad data was introduced to production, revert back to a good state in milliseconds.




