



One of the reasons behind the rise in data lakes’ adoption is their ability to handle massive amounts of data coming from diverse data sources, transform it at scale, and provide valuable insights. However, this capability comes at the price of complexity.
This is where data lineage helps.
In this article, we review some basic features of the open-source solution lakeFS that help to achieve lineage quickly, at minimum cost, and using data version control concepts you are already familiar with from managing code.
What is data lineage?
Data lineage is the process of tracking data from its origin to its final destination. It helps data practitioners understand how data is being transformed, stored, and used throughout its lifecycle.
Without an effective data lineage strategy, troubleshooting issues and ensuring data quality are very difficult tasks. Furthermore, the ever-increasing scrutiny of data practices, driven by regulations and compliance standards, calls for a reliable audit trail that outlines data processing activities.
Therefore, today, lineage is a key component of a data lake architecture, useful for:
- Compliance – enables demonstrating compliance with regulations by providing an audit trail of data processing activities.
- Efficiency – allows optimizing data processing workflows by identifying opportunities to automate processes and improve efficiency.
- Collaboration – facilitates communication and decision-making between data engineers and other stakeholders by providing a shared understanding of data.
And what is lakeFS?
lakeFS is an open-source, scalable, zero-copy data version control system for data lakes. Using Git-like semantics such as branches, commits, merges, and rollbacks, the lakeFS system helps data practitioners collaborate and ensure data manageability, quality, and reproducibility at all times.
lakeFS supports managing data in AWS S3, Azure Blob Storage, Google Cloud Storage, and any other object storage with an S3 interface (such as a MinIO or Dell ECS).
The platform smoothly integrates with popular data frameworks such as standard orchestration tools and compute engines. It uses metadata to manage data versions and supports every data format, in any data size, across all object stores.
Why is scalable data version control useful for data lineage?
The beauty of adopting a “Git for data” approach is that now you can take advantage of the best practices you’re familiar with from code and use them for data.
In this blog, I will walk you through a step by step notebook that will help you understand how to use Git-like actions on your data lake with lakeFS to achieve lineage by using different branches and commits for ingestion and transformation.
Achieve data lineage for your data lake – step by step guide
Perhaps the most common “oversimplified” question that data lineage helps answer is:
What did the original data look like before a transformation?
Often, it gets phrased as “Is this my fault? Or did I just get bad data?” ????
To answer this question, we would be leveraging the sample notebook data-lineage in lakeFS’s sample repositories.
To get started quickly, type the following commands in your terminal:
git clone https://github.com/treeverse/lakeFS-samples.git
cd lakeFS-samples
docker compose --profile local-lakefs upOnce your environment is up and running, we can access the notebook and the lakeFS server installed locally (passwords are available on the GitHub README document).
In this notebook, two data sets (employees and salaries) are ingested through two separate branches. Then, they’re merged together on a transformation branch. And finally, promoted to the production branch:

At the very end of the process, the lakeFS “Blame” functionality is used to trace the origin of a specific file or dataset.
This notebook includes everything you need to set up the environment. You are more than welcome to walk through the code. For simplicity’s sake, in this blog, we will jump straight ahead to the section and run all the setup commands above it:
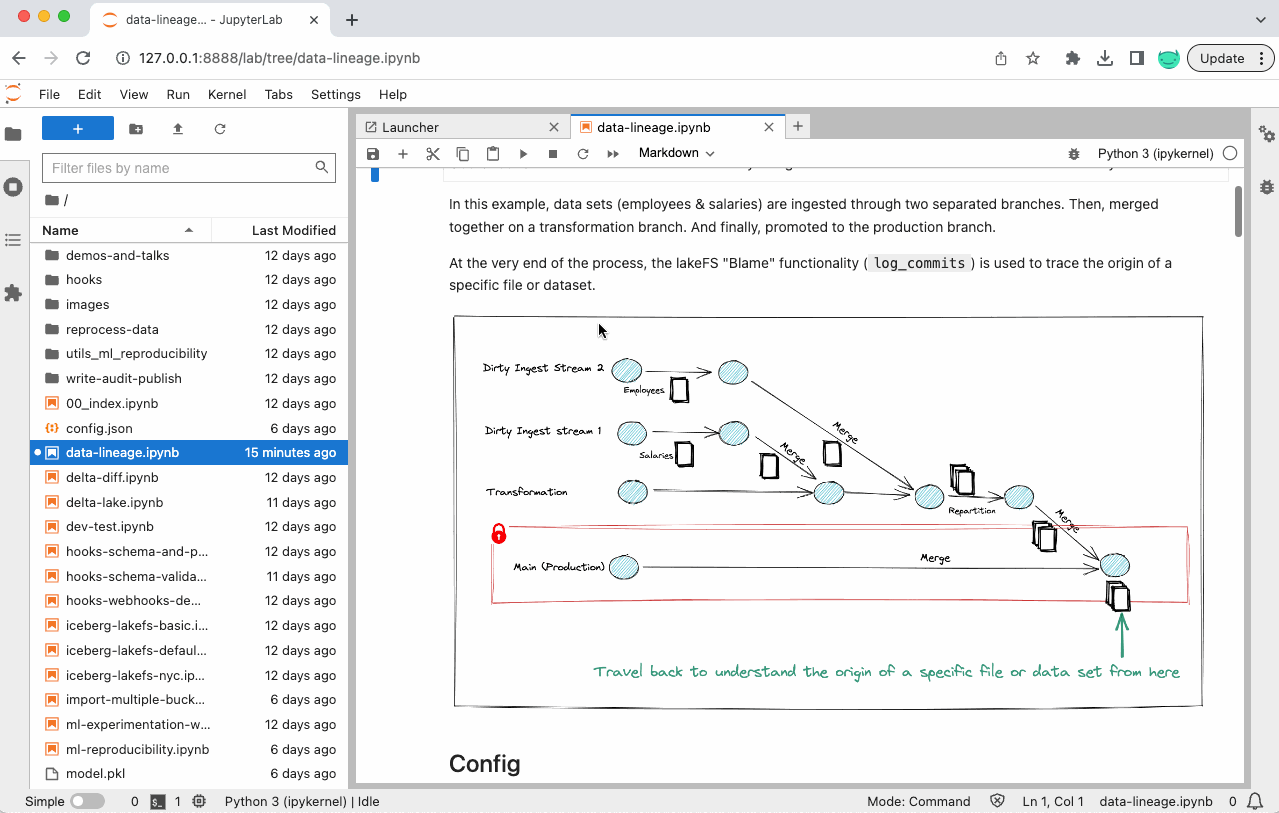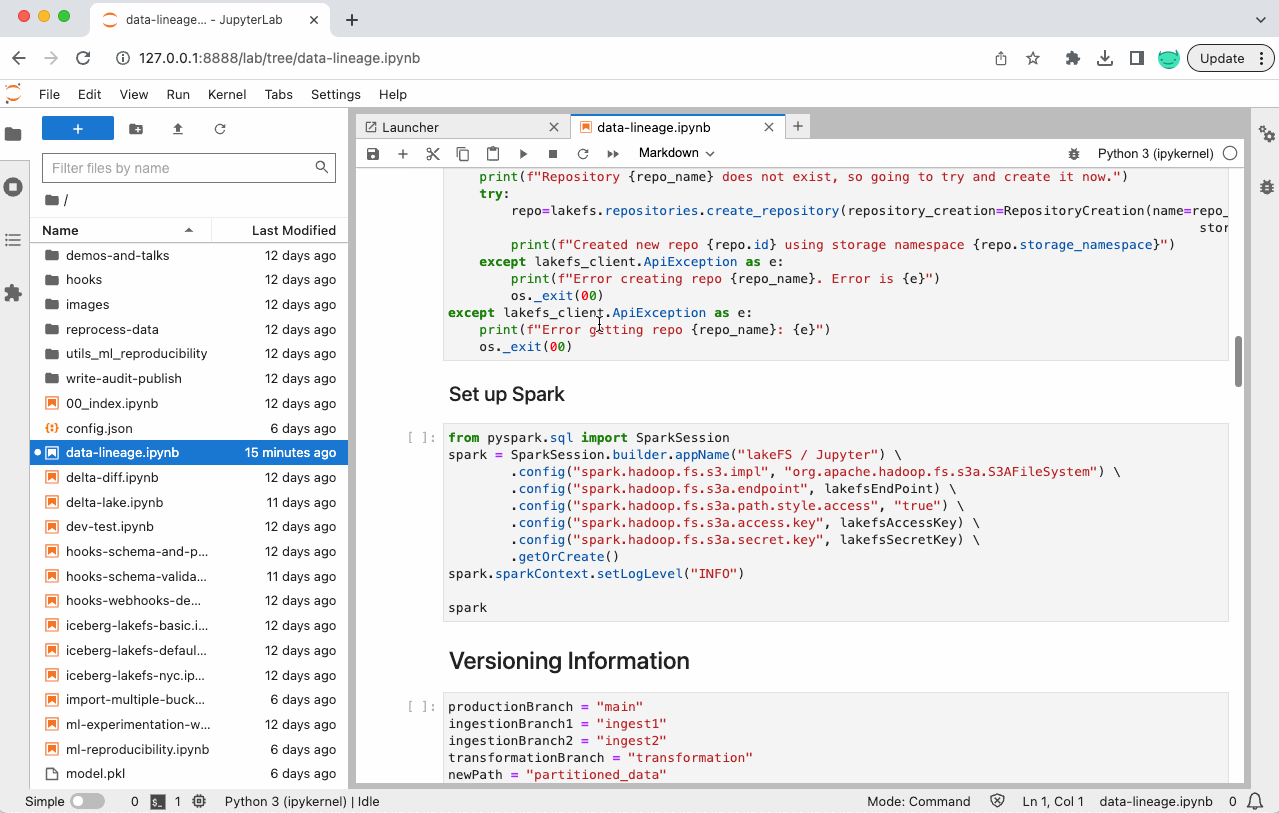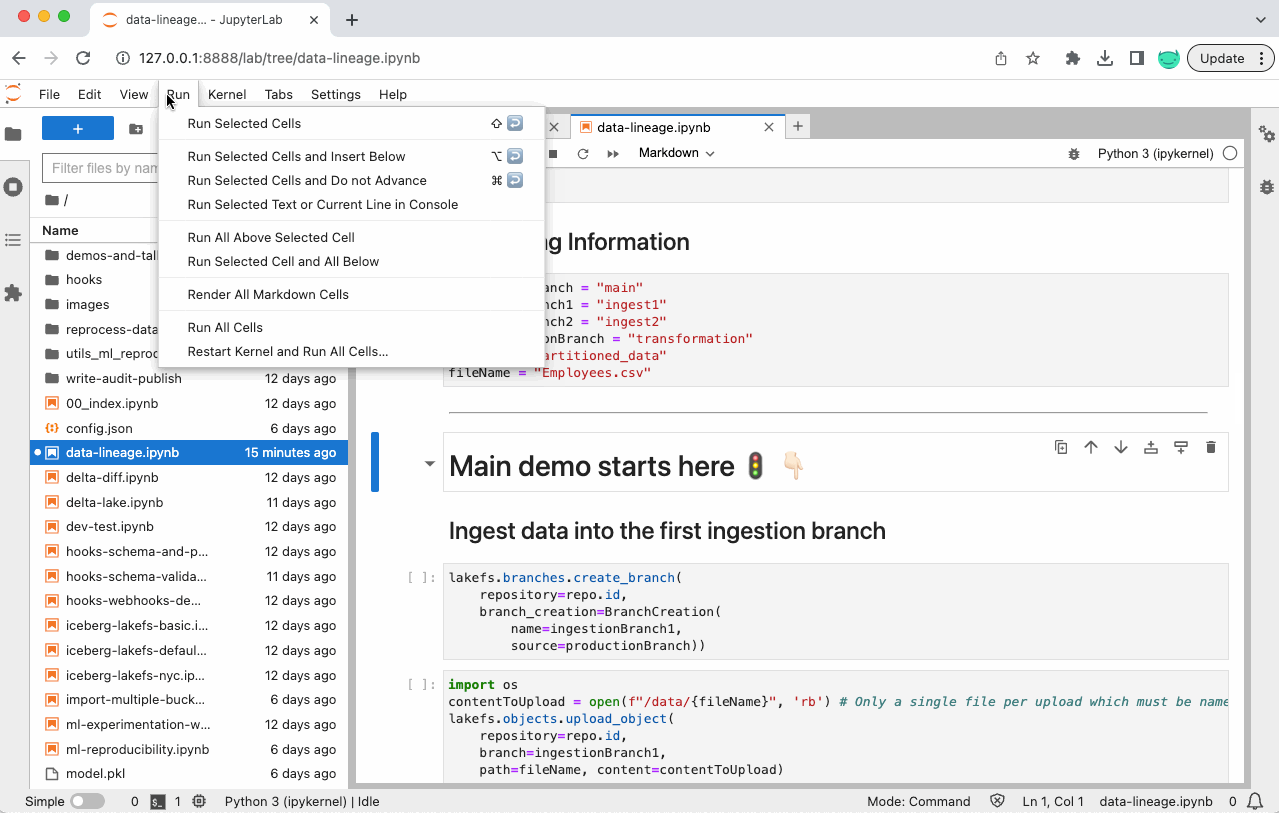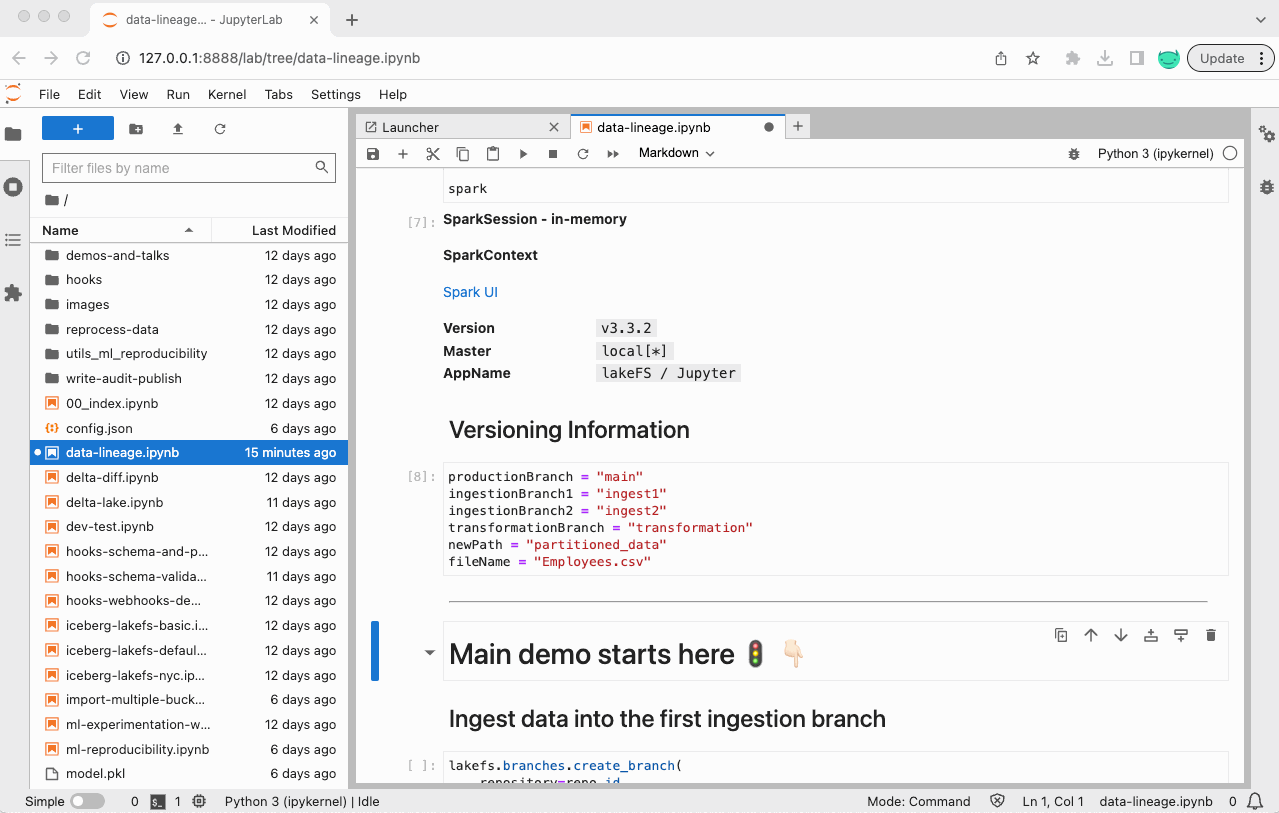
Step 1 – ingest data into ingest branches
Most commonly, a lakeFS repository will have a production protected branch. Any type of ingestion or transformation will be done in a separate branch. Among other advantages, this design enables an easy way to rollback production in case of an error.
In our example, we will first create an ingestion branch:
lakefs.branches.create_branch(
repository=repo.id,
branch_creation=BranchCreation(
name=ingestionBranch1,
source=productionBranch))Upload files to this branch:
import os
contentToUpload = open(f"/data/{fileName}", 'rb')
lakefs.objects.upload_object(
repository=repo.id,
branch=ingestionBranch1,
path=fileName, content=contentToUpload)???? Pro Tip: Upload simply copies data into the lakeFS repository. You can alternatively choose to run a zero copy import.
And commit these changes:
lakefs.commits.commit(
repository=repo.id,
branch=ingestionBranch1,
commit_creation=CommitCreation(
message='Ingesting employees IDs',
metadata={'using': 'python_api',
'::lakefs::codeVersion::url[url:ui]': 'https://github.com/treeverse/lakeFS-samples/blob/668c7d000b8c603b3f30789a8c10616086ef79c1/08-data-lineage/Data%20Lineage.ipynb',
'source': 'Employees.csv'}))???? Pro Tip: We are adding a metadata to the commit in the format ::lakefs::codeVersion::url[url:ui] this will create a button in the UI pointing to the value of the key and stitching the code version with the data version.
At this point, on the lakeFS UI, we should have a repository with an empty main branch and an ingest1 branch that contains the employees’ details:

Step 2: Ingest data into second ingest branch
We will repeat the same steps for a salaries data set ingested in a second ingest branch.
Create the branch:
lakefs.branches.create_branch(
repository=repo.id,
branch_creation=BranchCreation(
name=ingestionBranch2,
source=productionBranch))Upload the data:
fileName = "Salaries.csv"
import os
contentToUpload = open(f"/data/{fileName}", 'rb') lakefs.objects.upload_object(
repository=repo.id,
branch=ingestionBranch2,
path=fileName, content=contentToUpload)Commit the changes:
lakefs.commits.commit(
repository=repo.id,
branch=ingestionBranch2,
commit_creation=CommitCreation(
message='Ingesting Salaries',
metadata={'using': 'python_api',
'::lakefs::codeVersion::url[url:ui]': 'https://github.com/treeverse/lakeFS-samples/blob/668c7d000b8c603b3f30789a8c10616086ef79c1/08-data-lineage/Data%20Lineage.ipynb',
'source': '/Salaries.csv'}))Step 3: transform the data on a transformation branch
In this step, we will first create a transformation branch and merge both ingest data into it.
Creating the branch:
lakefs.branches.create_branch(
repository=repo.id,
branch_creation=BranchCreation(
name=transformationBranch,
source=productionBranch))Merging the ingestion branches:
lakefs.refs.merge_into_branch(
repository=repo.id,
source_ref=ingestionBranch1,
destination_branch=transformationBranch)
lakefs.refs.merge_into_branch(
repository=repo.id,
source_ref=ingestionBranch2,
destination_branch=transformationBranch)Alternatively, we could have run one less command and created the branch out of one of the ingestion branches.
Next, our transformation will join the two tables:
employeeFile="Employees.csv"
SalariesFile="Salaries.csv"
dataPath = f"s3a://{repo.id}/{transformationBranch}/{employeeFile}"
df1 = spark.read.option("header", "true").csv(dataPath)
dataPath = f"s3a://{repo.id}/{transformationBranch}/{SalariesFile}"
df2 = spark.read.option("header", "true").csv(dataPath)
mergedDataset = df1.join(df2,["id"])And then, re-partition the data by department:
newDataPath = f"s3a://{repo.id}/{transformationBranch}/{newPath}"
mergedDataset.write.partitionBy("department").csv(newDataPath)???? Pro Tip: You can take advantage of lakeFS’ RBAC to make sure users have permissions to read data only from their department.
Finally, as always, we will commit the changes:
lakefs.commits.commit(
repository=repo.id,
branch=transformationBranch,
commit_creation=CommitCreation(
message='Repartitioned by departments',
metadata={'using': 'python_api',
'::lakefs::codeVersion::url[url:ui]': 'https://github.com/treeverse/lakeFS-samples/blob/668c7d000b8c603b3f30789a8c10616086ef79c1/08-data-lineage/Data%20Lineage.ipynb'}))Once we complete these steps, our repository includes the following branches:
- Main – Empty (we have yet to promote any data to production)
- Ingest1 – Original employee data
- Ingest2 – Original salaries data
- Transformation – Merged data, partitioned by departments (i.e., salaries of all employees per department)

Step 4: Promote the data set to production
Now that we have had the opportunity to review the transformed data in isolation in our transformation branch, we can atomically promote all changes to production by merging the branch into main:
lakefs.refs.merge_into_branch(
repository=repo.id,
source_ref=transformationBranch,
destination_branch=productionBranch)????Pro Tip: Often, users will take advantage of hooks to automatically run quality checks before promoting data to production. For example, running automatic schema validation.
Step 5: Data lineage
Going forward, we can select any individual file or dataset (directory) and use the blame functionality to understand which commit it came from. Next, we can select the parent commit and browse the data sets as they appeared before the transformation.
In our case, it shows what were Salaries.csv and Employees.csv like before we merged and partitioned them:

The same thing can be done using the log_commits API for a dataset:
commits = lakefs.refs.log_commits(repository=repo.id, ref='main', amount=1, limit=True, prefixes=['partitioned_data/department=Engineering/'])
print(commits.results)Or an individual file:
commits = lakefs.refs.log_commits(repository=repo.id, ref='main', amount=1, objects=['Employees.csv'])
print(commits.results)????Pro Tip: Even when the data doesn’t sit on the same repositories, you can follow this exact method and achieve linage using commit metadata. For example, read more about how to Version Control Data Pipelines Using the Medallion Architecture with lakeFS.
Summary
In conclusion, achieving comprehensive data lineage for your data lake is a critical step in ensuring data quality, compliance, efficiency, and collaboration. While data lakes offer the capability to handle vast amounts of diverse data, this complexity can hinder troubleshooting and quality assurance without a robust data lineage strategy.
Data lineage traces data from its origin to its destination, shedding light on how data is transformed, stored, and used across an organization. As regulatory scrutiny increases, having an audit trail for data processing activities becomes indispensable.
This is where lakeFS, a scalable data version control system for data lakes, comes into play. By adopting a “Git for data” approach, lakeFS leverages version control concepts to achieve lineage effectively.
In this article, we outlined a step-by-step guide using lakeFS to establish lineage through different branches and commits for data ingestion and transformation. This approach empowers data practitioners to gain insights into the original state of data before transformations, enabling them to understand and manage their data with confidence.
Have more questions? Join us in our Slack community.




