

In the traditional setup, organizations had a centralized infrastructure team responsible for managing data ownership across domains. But product-led companies started to approach this matter a little differently. Instead, they distribute the data ownership directly among producers (subject matter experts) using a data mesh architecture. This is a concept originally presented by Zhamak Dehghani in 2019, and was quickly adopted as a leading approach.
The domain-driven approach makes data producers accountable for articulating semantic definitions, categorizing metadata, and establishing policies for rights and usage. Still, these companies keep a centralized data governance team on board to enforce these standards and processes.
It’s a win-win situation. While domain teams take care of their ETL data pipelines in a data mesh design, a centralized data engineering team helps find the best data infrastructure solutions for the data products.
But what exactly is a data mesh architecture, and how do you implement one? In this post we’ll explore the data mesh across various use cases and dive into its most challenging aspects.
Note: This is the fourth part of our series that dives into enterprise data architecture – you can find the previous parts here:
What is the data mesh architecture all about?
Data mesh is a decentralized data architecture that organizes data by business domain, giving data producers more control over establishing data governance principles. This enables self-service throughout the company.
Such a federated approach helps teams avoid many operational constraints that have been part and parcel of centralized, monolithic systems. Data mesh by no means excludes solutions such as data lakes or data warehouses. It just assumes they’ll no longer be used as a single, centralized data platform as the organization moves towards multiple decentralized data repositories.
Data mesh allows data to be treated as a product that users across the organization can easily access. As a result, teams get more flexible data integration and interoperable capabilities, allowing data users to consume data from many domains for business analytics, data science experiments, and other purposes.
What problem does the data mesh architecture solve?
Many companies have invested in a centralized data lake and a data engineering team with the hope of using data to drive business growth. But they soon realized how much of a bottleneck such a central data team becomes.
Many such teams fail to respond quickly enough to all the analytical queries coming from the management or product owners.
Data teams couldn’t handle the growing volume of such queries because they were always busy doing things like correcting malfunctioning data pipelines following operational database updates. To answer a query, a data practitioner needs to locate and comprehend the relevant domain data and study domain knowledge. Naturally, this takes a lot of time!
If you’ve already scaled up software development by decentralizing business into domains, engineering into autonomous teams, monoliths into microservices, and operations into DevOps teams, data mesh is the next step. It opens the door to scaling up data analytics via decentralizing the data lake into a data mesh.
With data mesh in place, producers can easily answer questions like: How does a product page update affect the speed of checkout and return rates?
Data mesh closely relates to approaches like domain-driven design, autonomous domain teams, and decentralized microservices architecture. The idea is to keep everything within the scope of domain teams, which are supposed to develop, create, and run their own online apps and APIs.
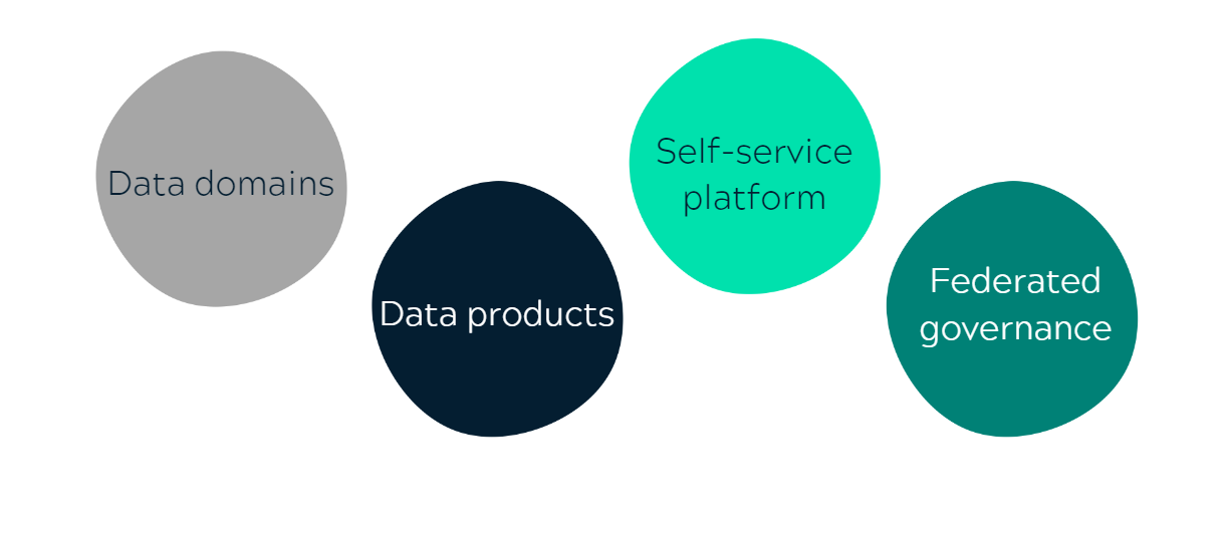
Key components of data mesh architecture
Domain ownership
This concept requires domain teams to take ownership of their data. Analytical data needs to be organized into domains, similar to how team boundaries coincide with the system’s environment. The domain-driven distributed architecture shifts analytical and operational data ownership away from the centralized data team and towards domain teams.
Data products
The notion of data as a product applies the product-thinking mentality to analytical data. This concept implies that there are data users outside of the domain. The domain team is in charge of meeting the demands of other domains by supplying high-quality data.
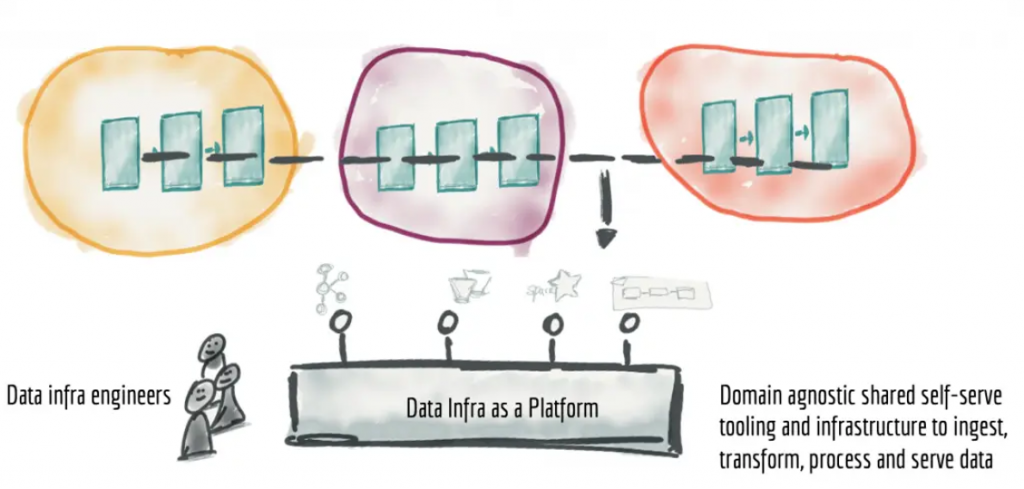
Self-service data platform
The self-service data infrastructure platform is designed to apply the platform concept to data infrastructure. The idea here is that a specialized data platform team offers domain-agnostic capabilities, tools, and systems for the development, execution, and maintenance of interoperable data products across all domains. The data platform team’s platform enables domain teams to consume and generate data products in real time.
Federated governance
The governance team advocates for standardization. This is how the federated governance concept provides interoperability of all data products. The primary purpose of federated governance is to establish a data ecosystem that adheres to corporate policies as well as industry regulations.
Advantages of implementing data mesh architecture
Cost savings
Instead of batch data processing, this distributed design of the data mesh architecture encourages the use of cloud data platforms and streaming pipelines to acquire data in real time.
Cloud storage offers an additional cost benefit by allowing teams to pay only for the storage that is requested. If you need to execute a project in a few hours rather than a few days, you can simply do it on a cloud data platform by acquiring extra compute capacity.
Data democratization
Data mesh designs enable self-service applications from numerous data sources, extending data access beyond more technical folks like data scientists, data engineers, and developers.
The domain-driven design lowers data silos and operational bottlenecks by making data more discoverable and accessible, allowing for quicker decision-making and freeing up technical users to prioritize tasks that match their skill sets best.
Less technical debt
A centralized data infrastructure incurs greater technical debt due to the system’s complexity and the teamwork necessary to maintain it. As data accumulates in a repository, the whole system tends to slow down.
Data teams can better satisfy the expectations of consumers and decrease technical constraints on the storage system by spreading the data pipeline based on domain ownership. Another way to make data more accessible is by creating APIs through which consumers can communicate, decreasing the volume of individual queries.
Interoperability
In a data mesh architecture, data owners agree ahead of time on how to define domain-agnostic data fields, facilitating interoperability. When a domain team structures its own datasets, they apply the required criteria to enable rapid and easy data connections between domains.
Field type, metadata, schema flags, and other fields are generally standardized. Consistency across domains helps data consumers interact with APIs easily and build applications that meet their business goals.
Compliance
A data mesh architecture enables greater governance practices by assisting in the enforcement of data standards for domain-agnostic data and access restrictions for sensitive data.
This helps organizations comply with regulations, and the nature of the data ecosystem facilitates compliance by enabling data audits. In a data mesh design, logging and tracing data allow for observability, allowing auditors to identify which users are accessing certain data and how frequently they do so.
Use cases of data mesh architecture
While distributed data mesh is still in its early stages of adoption, it’s assisting teams in meeting scalability requirements for popular big data use cases:
- Businesses frequently use chatbots to assist contact centers and customer service personnel. Since commonly asked queries might refer to several datasets, a distributed data architecture can provide these virtual agent systems with more data assets to work with and provide better answers during customer interactions.
- Using customer data, organizations may better understand their customers and create more tailored experiences. We can see this happening across a wide range of industries, including marketing and healthcare.
- Dashboards for business intelligence are another key use case for a data mesh architecture. As new initiatives emerge, teams often need specialized data views to analyze the performance of these projects. By making data more accessible to data consumers, data mesh architectures can satisfy this requirement for flexibility and personalization.
- Finally, there are machine learning projects. By standardizing domain-agnostic data, data scientists can connect data from disparate sources, saving data processing time. This, in turn, helps to speed up the number of models that migrate into a production environment, allowing automation targets to be met.
Real-world example of data mesh architectures
Saxo Bank is an interesting real-world use case for data mesh architectures. The company was looking to democratize data and transform the bank’s complicated ecosystem into a transparent and accessible platform.
The data mesh solution took the form of a data workbench that made data assets accessible and discoverable via a search engine. The data workbench also included product descriptions for each data asset, as well as other data like customer comments, so consumers can be certain that the data is reliable.
At a high level, after implementing data mesh, Saxo Bank saw lower client acquisition expenses, more efficient operations, and enhanced security thanks to fewer compliance issues.
Challenges of data mesh architecture
When developing a data mesh architecture, expect to encounter a few challenges. These are the most significant ones you may end up facing:
Budget limitations
There are a number of issues that put a platform project’s financial sustainability in danger. This includes not being able to pay for infrastructure, developing pricey applications, delivering data products, or maintaining such systems.
If the platform team is successful in creating a tool that effectively bridges a technological gap, but data quantities grow and data products get more complicated, the solution’s price tag may become prohibitively expensive.
Scarcity of technical skills
Delegating complete ownership to domain teams implies that they must be willing to commit to the project. They can recruit more people or train themselves, but this will add extra time and work to the initiative.
When performance drops substantially, problems may appear all over the place. No tools can fix this problem since you need to understand how things function in data engineering to do that.
Collaboration between domain and platform teams
There’s no doubt that data mesh adds a significant amount of work to areas that previously relied only on data reporting. You must find a way to persuade stakeholders that the effort is worthwhile. Once they’re on board, you’ll need to work with them to organize major releases.
For example, enhancing the platform may result in some unexpected changes. What if one domain is now testing new applications? You might see your project delayed for several months.
Monitoring requirements
The team must have the necessary tools to offer data products and monitor what is happening. Some domains may lack a thorough grasp of all technical metrics and how they impact workloads. Naturally, your platform team must have the resources available to detect and resolve issues such as overutilization or ineffectiveness.
The future of data mesh architectures
Data mesh has definitely moved beyond the theoretical today. Existing piecemeal solutions and DevOps best practices only address a specific technical need of a developer or engineer, automating a limited portion of the data ecosystem. It will be vital for businesses to develop robust end-to-end data mesh solutions to establish a durable and scalable architecture.
In the future, we’re likely to see an emphasis on automated platforms that help teams build resilient environments and provide native governance that delivers results.
Conclusion
Software engineering best practices like microservices served as inspiration for data mesh architecture. While applying such concepts to data processing is challenging, the benefits are substantial if done correctly.
While data lake may sound monolithic, it’s in reality implemented on a highly distributed technology, such as object storage. It allows data mesh and platform teams to deliver data products in isolated data environments. Using the right tools, you can divide that monolith into tiny data lakes for each product.
To minimize data duplication, you need a data lake abstraction – which the open-source solution lakeFS provides by letting each data product use its own repository while still consuming/exposing data to/from other repositories.
Data infrastructure teams can use lakeFS to provide each data mesh service with its own versioned data lake over the common object store. The Git-like operations bring forward all the missing capabilities, like data governance and continuous deployment of quality data.
Read this guide to data mesh to see how lakeFS helps implement it in a practical example.




