
Back when I was a 23-year-old student, I worked at an Israeli networking company as a BI analyst in the Operations department. My job revolved around modeling the company’s inventory which was quite costly and needed optimization.
At some point, I attended a meeting of the company’s management. When addressing the room, the CEO said that the reason behind the high inventory costs was expensive components. I knew that wasn’t true.
So, I stood up and said: “I’m afraid 80% of our costs actually come from low-cost, high-quantity items.” He didn’t believe me and bet me a box of chocolates that I was wrong. Still, he postponed making his decision. Two days later, he changed his decision and I had a lovely box of chocolates on my desk.

Why am I telling you that story? Because that was the moment when I realized how important understanding data is. And how critical it is to bring the right data at the right moment to people so they can make the right decisions.
I haven’t left the world of data since and have seen it evolve into what it is today: more massive, complex, and chaotic than ever before.
How can companies make data manageable? I believe that data version control is the way out. Keep on reading to find out why.
The constantly-changing nature of data in 4 examples
Example 1: Missing data
As you can see on the left-hand side of the figure below, some of the data was missing during the first calculation. You can see the NULL values in the price column, right? The data was late, but after a few days or a few weeks, it finally arrived and we could fill that column (on the right).

Source: lakeFS
Once the new data arrived, we could go back to the table and backfill this information. Instead of NULL, we have proper values now. This means that the data has changed from that original version we had previously.
Example 2: Fixing an error in data
Another example is fixing a mistake in data. We have values but for some reason they’re wrong. The mistake might derive from a human error, wrong calculation, or logic that collects the data.
But once we fix it, we can also fix the values that were incorrect. As you can see in the tables below, some values were correct and stayed the same while others were replaced by the correct values. This example illustrates how data changes as well.

Source: lakeFS
Example 3: Data coming from calculations
Another example is a scenario where data we had originally didn’t come from collection, but calculation – for example, a price estimation.
Imagine that we estimated a price using a certain algorithm and then realized there was a better logic available for doing that. Now we implement that logic back on our historical data to get better estimations of the past as well. Once we do that, the entire dataset will change into a (hopefully) better version of the data.

Source: lakeFS
Example 4: Work with unstructured data
Teams work a lot on semi-structured and unstructured data. Suppose you have a training set for a computer vision algorithm and you’re using a set of images that represent a good sample of the world for which you’d like to develop your machine learning model.
Now, you decided to replace some of those images with other images that represent the same point in the space you wish to create – but they do it in a better way. So, some of the images remain the same and some are replaced.
Another case would be looking at the problem from a different perspective – for instance, different properties of your images. All of these changes happening in the data make even the simplest things quite challenging.
How can teams deal with the constantly-changing nature of data?
To collaborate efficiently, team members need to be able to talk about a single source of truth with their colleagues. And these ingredients are a must-have for establishing a source of truth for data.
Collaboration
If you change the historical data, the team needs to have clarity as to what is the single source of truth. For team members to work concurrently on a fast evolving data set, they need a version (snapshot) of that data that is isolated for their use. Collaboration requires isolation for experimentation, a unified language of data versions so we can discuss the data, and a good way to introduce data back to the team from an isolated version of it.
Lineage
Lineage is the metadata that exposes the dependencies between our data sets. For example, which data sets were involved as inputs in the creation of a new data set. Obtaining Lineage was never a simple task, and now an additional complexity is added to it when each data set has several versions over time, an information that must be included in the Lineage metadata, or it wouldn’t be useful.
In some industries this information together with fast access to the data is required for auditing.
Reproducibility
You surely expect to get the same result if you run the same code over the same data, in other words, you expect reproducibility of your results. Teams need to know exactly what version of the input data set was used, with which version of the code, and have those available to get reproducibility.
Cross-collection consistency
No data set is an island. If we have updated a table and now have a new version of it, we must introduce all data sets that depend on it to reflect this new version. If we have not done so, our data lake is inconsistent, as one data set had changed while others were not yet affected. We need tools that allow us to introduce changes to our consumer, all mutually dependent data sets in one atomic action, avoiding inconsistencies.
Data practitioners need all of that to make things work smoothly. Here’s some good news: the world has already solved the problem of how to deal with data sets changed by a lot of people. It’s called version control.
Sure, version control was created for code, not data. If we tried to use Git over data right now, we’d likely fail. But the concept of version controlling our data the way we version control our code would be a massive help in managing modern, constantly-changing data.

Source: lakeFS
Version control for data – Solutions overview: DVC vs. Git-LFS vs. dolt vs. lakeFS
Let’s say I run my data over a relational database. Now, I’d like to make that relational database version-aware and manage tables, views, or a set of tables as a repository and version everything. This would allow me to use Git-like operations such as branching, merging, and commits. All that would happen naturally as an interface to the database.
So what do I need to change in the database? The answer is: basically everything.
If I want to have a simple structure of a database, I get two main components:
- A storage engine – this is where I keep the data in a data structure that allows retrieving and saving it into the database, with decent performance. In my case, that storage engine needs to provide Git-like operations too.
- A database server – the other part of the application is a parser that parses the SQL queries, an executor that executes them, and an optimizer that makes sure it all happens as fast as possible. These three components build the database server, usually optimized for the storage engine the database has.

Source: lakeFS
If we want to make the storage engine version-aware, we need to make the application version-aware – and then the entire database changes.
Let’s take a look at a few solutions available today that provide data practitioners with the ability to version control data just like code. We will cover in this section DVC vs. Git-LFS vs. dolt vs. lakeFS
Solution 1: Dolt
A great example of an open-source project building a versioned database is Dolt, based on a storage engine called Noms (also open-source). It provides Git-like operations for data.
The relevant use case would be a company using a relational database for their data and wishing to continue using it and also have version control capabilities. How would that work? Let me explain the most important components of the Dolt database – the Noms storage, which relies on a data structure called Prolly-trees.
A Prolly-tree is a block-oriented search tree that brings together the properties of a B-tree and a Merkle tree. Why was it important to merge those two logics? A B-tree is used to hold indices in relational databases – it allows to balance the way you structure it and provides a good balance between the performance of reading and writing from a database.

Source: Dolt Documentation
On the other hand, we want the database to support Git-like operations, so we want this tree to resemble a Merkle tree, which is the data structure we use in Git.
The logic is that we want to save data according to the hash of its content. So the data would still be pointed to from the tree leaves. We would have sets of actual data from which we calculate the hash. The bark and root of the tree would be addresses that are calculated from the content hash.
So we have a tree representing the table and the different hash representing this change in its content. Since other rules haven’t changed or hash didn’t change, we can imagine that it would be easier to calculate diffs between such trees, calculate and implement marriages, and so on. This is how Prolly-tree helps us combine B-tree and Merkle tree into an efficient way of versioning tables within a relational database.
Still, Dolt won’t help you if your data isn’t managed in a relational DB, or if you wish to keep your data in place. It would also be impossible to manage on a petabyte-scale. If you need high performance, this structure would be less efficient. And if you rely heavily on unstructured data, then you definitely need a different solution.

Source: lakeFS
Solution 2: Git LFS – another Git for data option
We started with the assumption that it would be great to have Git for data. But Git doesn’t scale for data. However, we can use an add-on that helps to combine data and code management, Git LFS.
This idea comes from the world of game development. Game developers usually deal with the game code but also tons of artifacts – mostly binaries that impacted what the game looked like. They had to manage those assets together with code, so their repositories became very strange and extremely heavy – they were checking in and out those very large binary files. Things got complicated quickly.
So game developers built an add-on to Git that allows them to avoid doing that if there’s no need. The logic behind it is simple and relies on managing metadata. This use case grew on people who do machine learning and research because they also have files that aren’t code and are a little larger than what you’d expect – this includes files that manage code. They want to keep them together because of the connection between the model and the data it was running on.
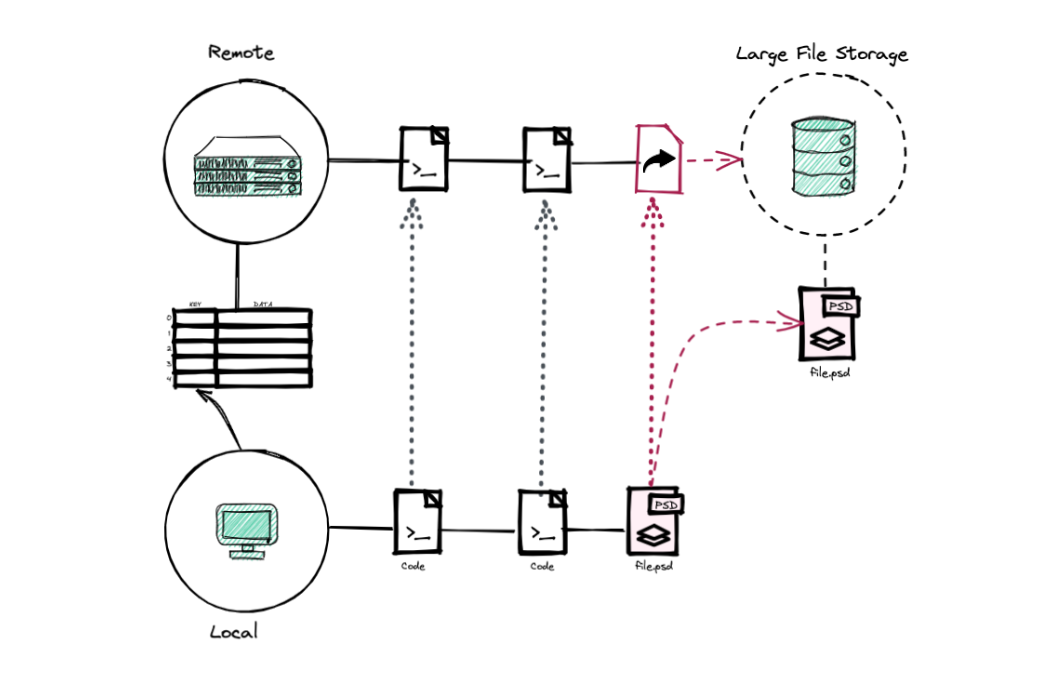
Source: GitLFS documentation
This is how Git LFS was born and found its way into the world of data. It’s basically Git where users have large file storage added to the actual repository for saving those large binary or data files to be managed with Git LFS.
Git LFS calculates a pointer to this data and when the repository is checked out, it’s not files but pointers to the files. Only when users decide that they want those files locally do they call them and actually create a local copy. The back and forth between the large file storage and the local code version is updated only if the user is actually editing a binary file, and only for that file.
This is a very simple idea that makes it all easier to manage – also because it’s format-agnostic. Since we create a path/pointer to the file, we don’t care about its format anymore.
In Git LFS, your code repository is a Git repository. If you’re using the service, then the code is hosted there and files as well – meaning you have to lift and shift your data to coexist with your code, wherever it is.
Source: lakeFS
Solution 3: DVC (Data Version Control)
Update: DVC was acquired by lakeFS.
DVC (Data Version Control) is a project inspired by Git LFS and built with data scientists and researchers in mind. The idea was to give them something like Git LFS with additional capabilities suitable for use cases data scientists encounter.
To follow this scenario, data needs to stay in place – in local storage, object storage, or anywhere else. Data retrieval might take some time because files may be big. On top of that, data scientists work in teams. They will benefit from a caching layer shared between them and their teammates.
How does that work? When you retrieve a file, it’s cached on the DVC server and very quickly made available for use. You no longer need to have someone load the file into a remote Git repository like Git LFS.
So, the market needed a solution that allows doing all these things efficiently for data scientists. Enter DVC. DVC’s architecture looks like Git LFS, plus the required improvements that address the requirements listed above.
With DVC, you get remote code storage that is actually a Git server and every mode of data storage – any object storage on any cloud provider or hosted on-prem. The SSH access allows you to access fire systems and local storage.
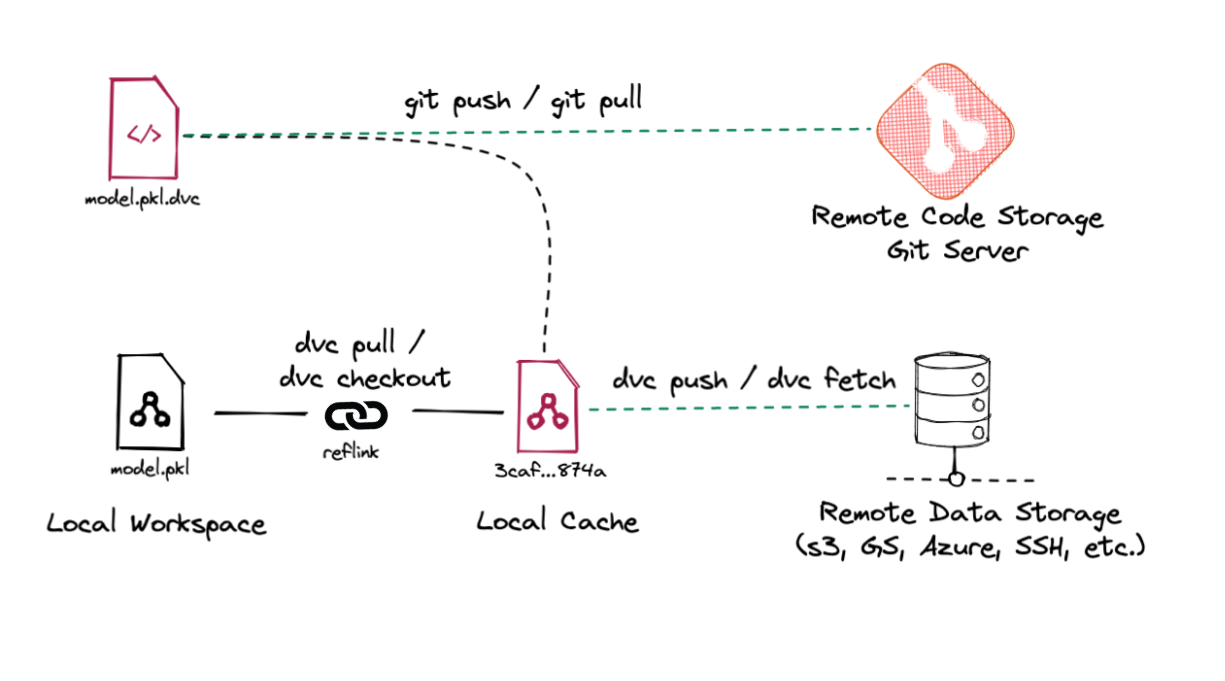
Source: DVC Documentation
Now all the data stays in place and you can edit and see it as part of your repository. You also have a caching layer (local cache) – when you get a file, it’s stored in the local cache to ensure better performance when others pull that file. That’s why DVC works better for data science than Git LFS.
For data science and machine learning use cases, DVC can support both structured and unstructured data.
What’s missing from DVC? If you’re a relational database person, the solution doesn’t work that well. When operating on a petabyte-scale and using hundreds of millions of objects, caching becomes unrealistic. So, it’s time to check out the next solution. 
Source: lakeFS
Solution 4: lakeFS

Modern data operation Source: lakeFS
Consider a data operation that has many data sources saving data into object storage (S3, min.io, Azure Blob. GCS, etc.), and ETLs running on distributed compute systems like Apache Spark or Presto. Those ETLs might be built out of tens or hundreds or even thousands of small jobs orchestrated by Airflow DAGs. There are numerous consumers consuming the data – ML engineers, BI analysts, or the next person to write an ETL over data for some new use case.
Most of us are either already running such data operations, or will do so soon enough..
We need a different solution here than the ones we have seen so far:
1. We want to keep the data in the object storage.
2. We analyze the data using remote clusters of compute so local copies or local caching are irrelevant.
2. We want to operate in a high scale of git-like operations, performing thousands of actions a second, so having Git in the background, as DVC does, does not work.
3. We may manage up to billions of objects in our data lake, and need to support efficient diff and merge operations.
The suitable candidate in this case is the open source project lakeFS.
lakeFS works like a wrapper over parts of the data lake that you’d like to version control. It’s an additional layer that provides Git-like operations over the object storage. lakeFS comes in handy when you want to develop and test in isolation over object storage, manage a resilient production environment through versioning, and achieve great collaboration. This version control solution supports both structured and unstructured data and is format-agnostic, ensuring compatibility with all the compute engines in use today. It was built to be highly scalable and keep excellent performance.
Suppose you have an application running on Spark in Java, Scala, or Python. You can use a lakeFS client together with your code to take advantage of Git-like operations. Your client will be communicating with the lakeFS server to read/write the metadata while your application accesses the data in your object storage for read/write operations. If a client can’t be used within the application, one can use the lakeFS gateway, which allows to read/write data through lakeFS.

Source: lakeFS
How do you scale version control to billions of objects? You use aprolly tree! While in Dolt (Nums) the prolly tree holds in its leaves the address of a triplate, with lakeFS it holds addresses of objects. The next layer of the prolly tree holds meta-ranges, that are ranges of ranges. So we have a two-layer prolly tree. A commit (or a branch, or a merge) is the set of meta-ranges that specify the data it points to.
For more information on lakeFS internals, read the lakeFS Versioning Internals section in lakeFS documentation.

lakeFS data model: Prolly tree of depth 2. Source: lakeFS
Is there anything you can’t do with lakeFS? If you don’t have an object storage, the solution won’t bring you much value. lakeFS also doesn’t have any specific use case features like DVC does when looking at specific users. It’s more of an engine that takes care of the data itself, allowing all applications to run over it
Source: lakeFS
Wrap up
If data practitioners use the right data version control tool that handles the scale, complexity and constantly-changing nature of modern data, they’re bound to have an easier time managing it. They can transform a chaotic environment that is hard to manage into a manageable environment where they have full control – they know exactly where data comes from, what has changed, and why.
That way, data practitioners can go back to being that person in the room that corrects the CEO when they’re about to make a decision based on data.
And here you have it – the full advantages of each one of those solutions and use cases where they work best. Leverage these solutions and make your life easier when managing the chaos of data. Or, as Paul Singman loves to say: Mess with your data, but don’t make a mess of it.

Source: lakeFS
Watch the presentation:
This post is based on Einat Orr’s qcon talk – watch the full talk here .
For questions to Einat, please join our slack channel: https://lakefs.io/slack





