

The MLOps domain is spreading at an accelerating pace. In recent years, we’ve seen more ML products and MLOps tools than we probably need.
Today, there are hundreds of tools trying to solve a bunch of problems in different ways, with some of them promising end-to-end solutions. This usually makes data practitioners confused when they try to pick the right set of tools to use.
As the ML domain becomes more complex and far-reaching, we need to start tracking a lot of elements – from data to ML model parameters. This is one of the top MLOps challenges.
What’s the current status of source control tools in the MLOps universe? And how to pick the best tool for the job?
Intro to the MLOps landscape
MLOps is clearly on its way to standardizing the world of products based on ML. Google, which coined the term, has a nice snapshot of the domain that shows the sheer amount of work and tools we need when getting an ML product off the ground.

Looks quite complicated, doesn’t it?
It all starts with configuring your model, collecting your data, and preparing it, and ends when you serve the product to end users.
But is the data practitioner responsible for all of these elements? Not really. One glance at the image tells you that we need people from various disciplines like data scientists, DevOps, software engineering, and more.
Still, as data practitioners, we need to understand the big picture and the importance of each part of the process – as well as the key principles of MLOps.
Principles of ML development
The principles of MLOps are no stranger to us, we just need to adapt them from the world of software development to the MLOps universe.
I’m talking about things like:
- Iterative-incremental development
- Automation
- Continuous Deployment
- Versioning
- Testing
- Reproducibility
- Monitoring
So, how do you achieve the holy grail of iterative-incremental development in MLOps?
This aspect is related to another capability: reproducibility.
When experimenting with an ML model, we want to be able to repeat the same experiment in every step of the process.
What I mean here is that this road is pretty clear: you design a product, develop it, and then serve it to your users.
But taking proper care to monitor the end product’s performance is important as well (that’s the backward part of the iterative process). It helps you design a better one next time.
This makes reproducibility one of the key goals of an MLOps team. It’s also an indication of the maturity of our process, like CI/CD we know from software development.
In the world of MLOps, the reproducibility practice we build needs to touch a lot of elements: the training code, data, and ML models, as well as datasets and the different parameters of the model.
Reproducibility is about letting teams repeat every step of the process, like data processing or model training – and repeating that, getting the same results.
Now that we understand the importance of source control in MLOps, how do we choose the best tool for the job?
State of MLOps tools in 2024
When we started working on lakeFS, we realized that data engineering is a massive field and different parts of it tend to get very crowded. MLOps is no exception.
We often get questions like: “How do you integrate with this tool or how do you get data from that tool?”

Clearly, the ML domain was becoming pretty crowded. Since we’re open source, giving back to the community means a lot to us. We decided to develop an annual review of the different tools in the field to track the new developments and check where the industry is headed.
Take a look at the second column on the right side. MLOps tools occupy a lot of space on the map. Some may argue that by now MLOps is overfitting since there are so many tools that do similar things and promise a lot more. It’s really hard to understand what makes them different.
How does one navigate this?

End-to-end MLOps tools are a pretty big category today, and it seems that most tools are trying to offer solutions that take care of the entire process.
Some of them started from a single section like model training, and gradually expanded from there. Then there are tools that were developed by large organizations and then released to open source (MLflow from Netflix and KubeFlow from Google are some such examples).
You’ll find a bunch of commercial companies with a paid product but with some OSS strategy or a free tier.
The problem? Most of these tools offer good solutions to some parts of the process but fail to address other parts.
Let’s take a look at the close-up:

One way to make sense of it all is by understanding what a particular tool focuses on. You have data-centric tools that focus on the data itself, realizing that this is the bottleneck of ML processes. They put data management at the center.
You can also differentiate between ML-centric tools and others. A good example of the former is Tecton, the latter Redis, a general database that could also serve as a feature store.
What about ML observability and monitoring? Tools that focus on model quality are gaining a lot of momentum right now and new offerings are popping up all over the place. If you pick some end-to-end tool that doesn’t have enough monitoring, you need to make sure that it can integrate with one of the tools from this category.
Making the right choices in such a dense market can be challenging. You need to factor in the aspects important to your organization and the particular requirements of your ML projects.
How to pick the right MLOps tooling
By category covered
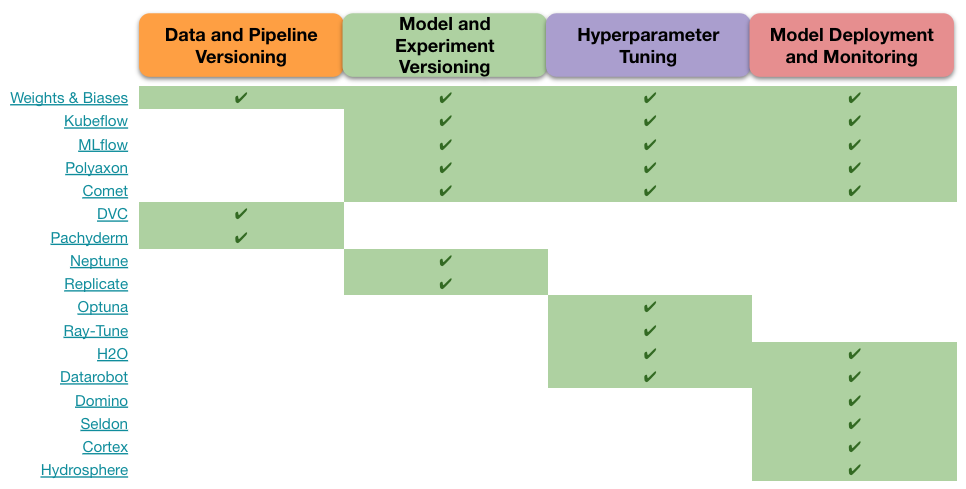
With reproducibility and source control in mind, MLOps tools can be divided by their coverage of these four functionality categories:
- Data and pipeline versioning
- Model and experiment versioning
- Hyperparameter tuning
- Model deployment and monitoring
Now you’re bound to face a dilemma: do you want a single tool that delivers all four or one that delivers just one or two functionalities but focusing on them will bring more depth and opportunities?
By integrations covered
You can also compare tools by their integration with common libraries and data science tools in the organization.
Found a promising solution to your problem? It might be lacking integration with some other tools in the ecosystem, so be sure to check it.

Other approaches to compare MLOps tools
There are many other ways to compare tools. You can take into account the community around the product, the ease of use, whether it’s cloud-native, the scale of your data and the production model, and support of different formatting.
Now that we addressed this massive MLOps obstacle, let’s go back to what really helps teams achieve iterative development in ML.
Here’s why you need source control for ML development
Einstein once said, “Insanity is doing the same thing over and over and expecting different results.”
If Einstein lived a century later and saw what data practitioners are facing, he’d probably change his mind.
The reality of our jobs is somewhat more unexpected and complicated than that. A lot of times we repeat the same experiment to get different results. The reasons behind this range from new or late-arriving data to someone changing the schema without us knowing or simply not running on the exact same environment (on-prem vs. cloud).
Why do we need to get the same results in ML experiments?
Consistency
We want our model to produce the same result given the same data. This is how we build trust. If we can get the same result using the same experiment, the users’ experience won’t be consistent either.
We want to be able to change a single element like the core of the model and make everything else constant. And see how the result has changed.
Safety
Another reason is safety. Sometimes, something changes for the worse and we want to go back to the last known good state. We may want to reproduce the problem or revert it.
To do that, we need all of the elements on the way to be versioned, so that our baseline will produce the same results.
Regulation
Sometimes, we need to reproduce the previous state of the system or even of the data because of regulations.
When we get a different result than we expected, it’s key to separate it all into base elements:
- Function,
- The input of the function,
- The output of the function.

As you know, data may change without us knowing about it. So, at the basic level, data versioning should be there to give us snapshots of a point that is constant in time.
How to version your input (data)? Enter lakeFS
We saw many tools that help to manage the output like Kubeflow or Airflow. But what about managing the input – more specifically, data?
Some tools can do it up to a specific scale. Like DVC, where the pointer is saved to a file inside your repository. Other tools that do data version control have limited functionality and integrations with other tools in the ecosystem.
lakeFS is an open-source project that fills this gap.
It allows teams to manage their data using Git-like operations (commit, merge, etc.), scaling to billions of files and petabytes of data. Bringing best practices from software engineering to data is a smart move. In this scenario, you add a management layer on top of your object store like S3, and it turns your entire bucket into something like a code repository.
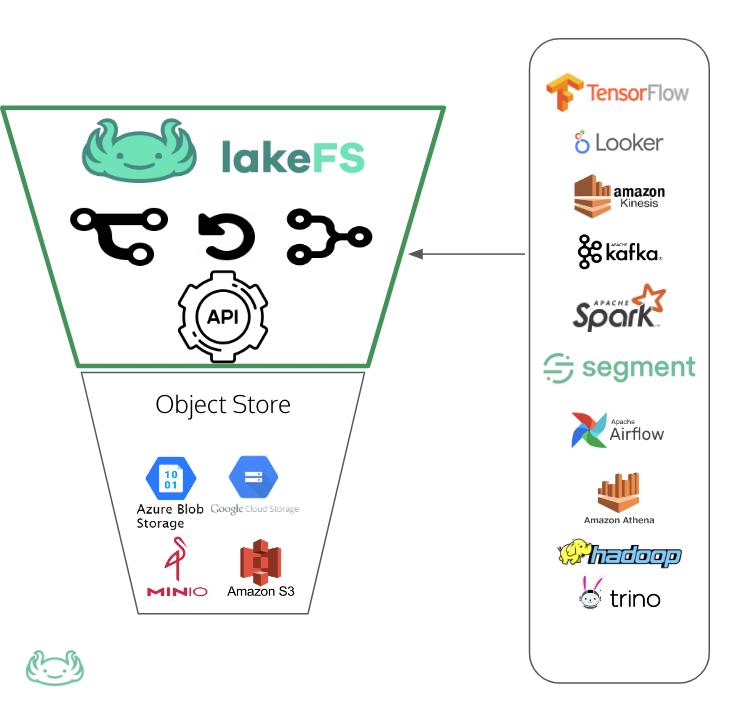
lakeFS handles a small part of the MLOps flow, but it tries to be a good citizen inside the ecosystem by integrating with all of the tools.
Another important part of the source control is isolation and lakeFS enables it too.
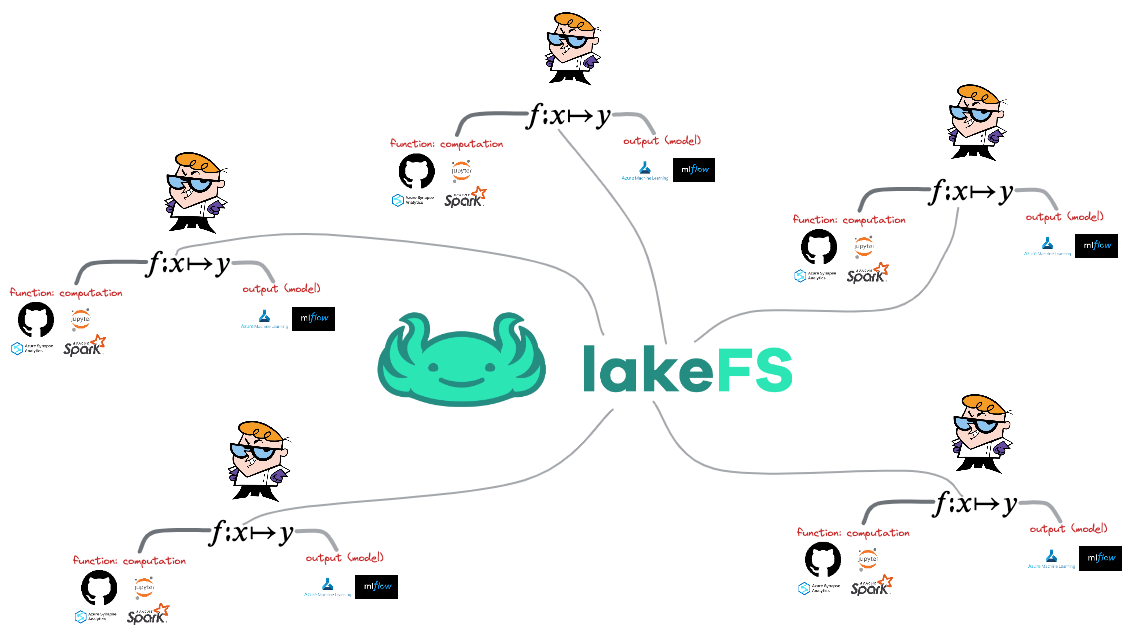
When you’re working on a feature branch in Git, you don’t have to worry that it will change the code in the main or production branches. Data practitioners know how painful that can be when dealing with a huge scale of data – after all, few managers will allow you the budget to duplicate it.
With lakeFS, several data practitioners can work on the same data – for example, they can create a separate branch for every experiment. Tagging data can be used to represent specific experiments, and this opens the door to reproducing these experiments using the same tag.
Once the change works for you, you can push it or merge it back to the main branch and expose it to consumers. Or you can easily undo changes, without having to go file by file as you would in S3. You can revert the change and go back to the last good status.
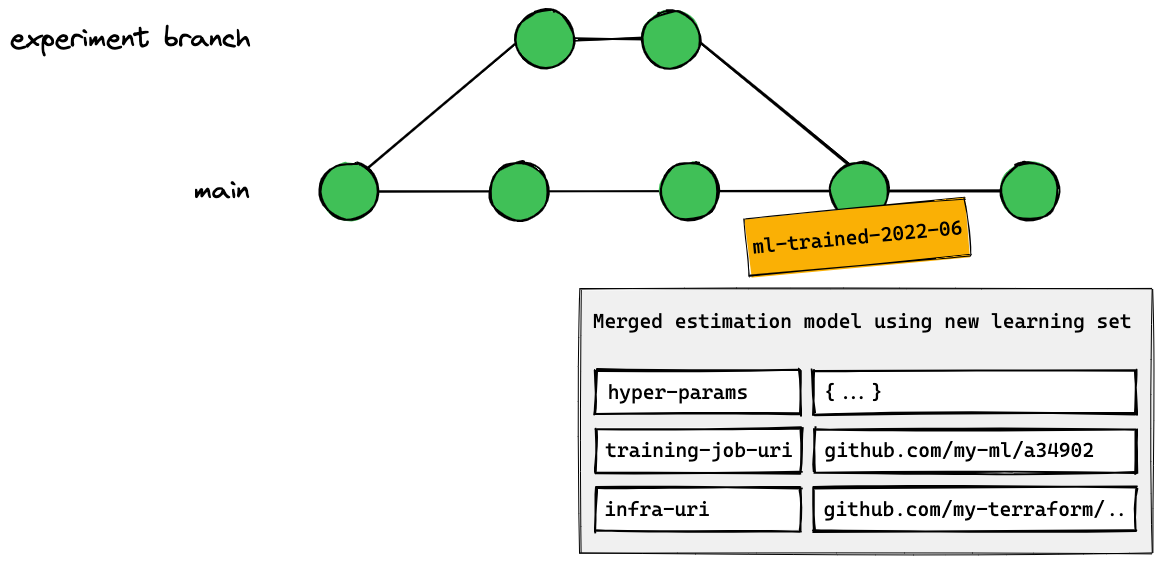
Example ML workflow with lakeFS
- Want to work on a new feature? Create a branch for it.
- Run changes to that branch in full isolation.
- If the changes don’t work for you, delete the branch and forget about it.
- Alternatively, you can test it (or automate those tests).
- Finally, you can merge the branch back to the main.
Wrap Up
In this post we explored to improve ML pipeline development with reproducibility using lakeFS. We first looked into the current ML landscape and analyzed the principles of ML development. We then snuck a peek into the state of MLOps tools as of 2023 and discussed how to pick the right tools for your business needs. Finally, we delved into how to get reproducible experiments with the ML tools available and discussed the importance of getting the same results in your ML experiments with a focus on consistency, safety and regulation.
Ready to test out lakeFS for your own reproducible ML experiments? Start here.




