


12 Best Data Quality Tools for 2026

Idan has an extensive background in software and DevOps engineering....
Table of Contents
As companies recognize the value of data and data management, teams are under greater pressure to increase and maintain high data quality. The growing number of data sources and increasing complexity make it challenging for teams to continuously evaluate and improve data quality.
There are many different data quality tools on the market, so how do you find the right one for your use case?
In this article, we dive into the topic of data quality management tooling and share a list of top data quality tools, from free and open-source solutions to heavy-duty business software packages.
What are Data Quality Tools and How are They Used?
Data quality tools help to streamline and often automate data management activities required to guarantee that data remains fit for analytics, data science, and machine learning use cases. Such tools help teams assess existing data pipelines, identify quality bottlenecks, and automate various remedial tasks.
Profiling data, tracing data lineage, and cleansing data are all examples of processes connected with assuring data quality. Data cleansing, data profiling, measurement, and visualization tools help teams understand the format and values of the acquired data assets and their collection.
These tools will highlight outliers and mixed formats. Data profiling acts as a quality control filter in the data analytics pipeline. And all of these are key data management functions.
12 Top Data Quality Tools
| Tool | Release date | OSS | No code | AI/ML based monitoring | On-prem available |
|---|---|---|---|---|---|
| Great Expectations | 2017 | ✅ | ❌ | ❌ | ✅ |
| Deequ | 2018 | ✅ | ❌ | ❌ | ✅ |
| Monte Carlo | 2019 | ❌ | ✅ | ✅ | ❌ |
| Anomalo | 2021 | ❌ | ❌ | ✅ | ✅ |
| Lightup | 2019 | ❌ | ✅ | ✅ | ✅ |
| Bigeye | 2019 | ❌ | ❌ | ✅ | ❌ |
| Acceldata | 2018 | ❌ | ❌ | ❌ | ❌ |
| Observe.ai | 2017 | ❌ | ❌ | ✅ | ❌ |
| Datafold | 2020 | ✅ | ❌ | ❌ | ✅ |
| Collibra | 2008 | ❌ | ✅ | ✅ | ✅ |
| dbt Core | 2021 | ✅ | ✅ | ✅ | ✅ |
| Soda Core | 2022 | ✅ | ❌ | ✅ | ✅ |
Here’s a look at some of the data quality tools and testing frameworks that can help teams get closer to high-quality data.
1. Great Expectations

This open-source data validation tool is easy to add to your ETL code and steer clear of any data quality issues. A SQL or file interface can be used to test data. Because it was designed as a logging system, it can be combined with a documentation format to generate automatic documentation from the specified tests.
Great Expectations also allows you to construct a data profile and define expectations for successful data quality management, which you may discuss throughout testing.
2. Deequ

AWS has created an open-source tool to assist developers in setting up and maintaining metadata validation. Deequ is an Apache Spark-based tool for developing “unit tests for data,” which check data quality in huge datasets.
The tool is designed to work with tabular data such as CSV files, database tables, logs, and flattened JSON files – in other words, anything that can fit into a Spark data frame.
3. Monte Carlo
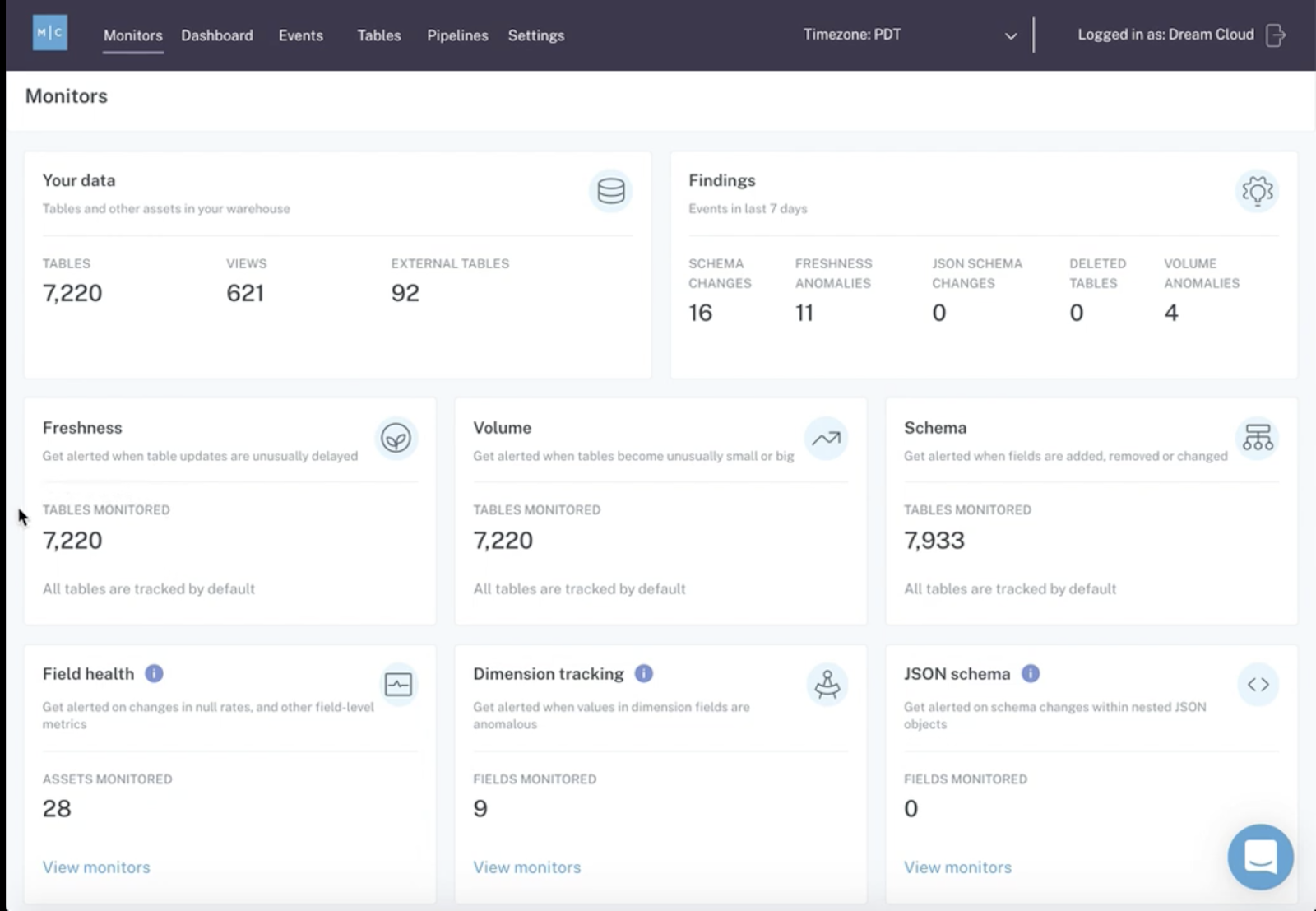
This is a framework for establishing observability (an important data quality metric) without the use of code to take good care of your data assets.
Monte Carlo uses machine learning to infer and interpret the appearance of your data, detect and analyze data concerns, and convey warnings via links with traditional operational systems. It also enables the investigation of underlying causes. Definitely a must-have among data quality tools.
4. Anomalo
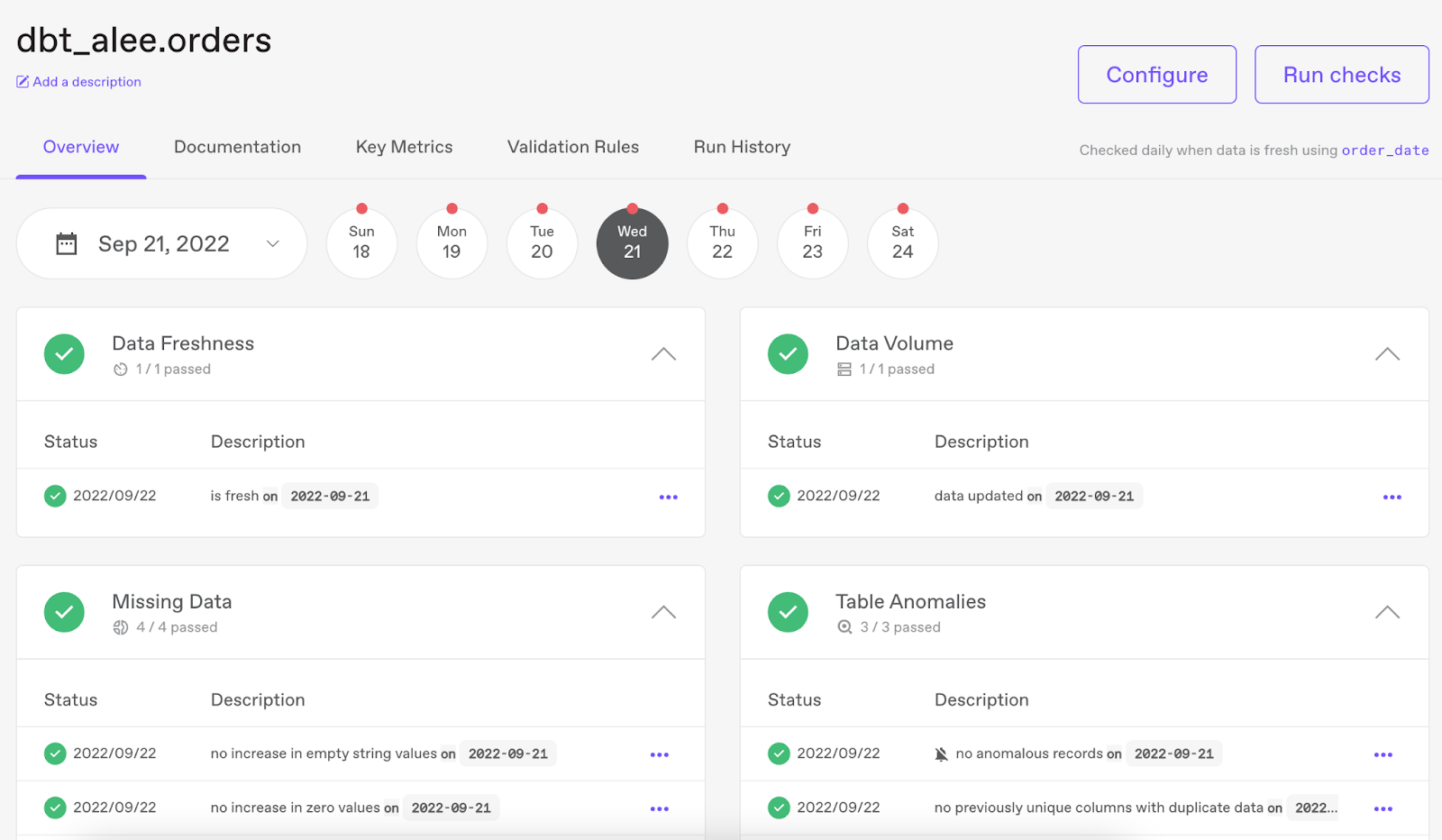
Anomalo assists teams in staying ahead of data issues by detecting them automatically as soon as they occur in the data and before they affect anyone else. Data practitioners may connect Anomalo to their data warehouses and begin monitoring the tables they care about right now.
The ML-powered tool can automatically grasp the historical structure and trends of the data, alerting users to a variety of issues without the need to specify rules or set thresholds.
5. Lightup
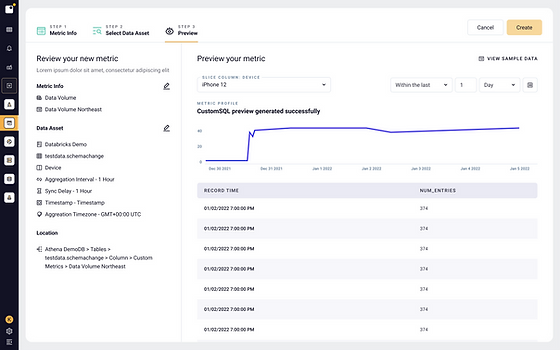
Lightup makes it simple for data professionals to implement and scale prebuilt data quality checks on enormous amounts of data. Deep data quality checks can be implemented in minutes rather than months.
The technology also enables teams to swiftly and efficiently extend data quality checks across business data pipelines using time-bound pushdown queries – without losing performance. In addition, an AI engine may automatically monitor and detect data abnormalities.
6. Bigeye
Another interesting option among commercial data quality solutions, Bigeye continuously checks the health and quality of data pipelines, so teams never have to question if their data is trustworthy. Global data pipeline health and rigorous data quality monitoring maintain data quality, while anomaly detection technology detects problems before they impair business operations.
The tool also includes lineage-driven root cause and effect analysis to provide immediate insight into the causes of problems and a clear route to fixes.
7. Acceldata

If you’re looking for enterprise data quality solutions, Acceldata might be a good pick. It includes tools for monitoring data pipelines, data dependability, and data observability.
Acceldata Pulse helps data engineering teams gain an extensive, cross-sectional view of complex and often coupled data systems. It’s one of the most popular observability solutions for the finance and payment industries.
The tool can synthesize signals across many layers and workloads on a single pane of glass. This technique enables several teams to collaborate to assure dependability by forecasting, recognizing, and resolving data issues. However, users have reported issues with changing metrics and importing data from external sources.
8. Observe.ai
This solution focuses on call centers, BPOs, and any other support services vertical, where it aims to provide complete visibility of brand interactions with customers. Oberve.ai capabilities like speech analytics and quality management are game changers in the business.
Unlike the other data quality tools on this list, it includes automatic voice recognition, agent help, and natural language processing. It’s not about assuring data veracity; rather, it’s about improving agent performance and customer service experiences.
Some users say that it’s more expensive than other tools and falls short in terms of reporting. Value charts, for example, don’t show any comparisons.
9. Datafold
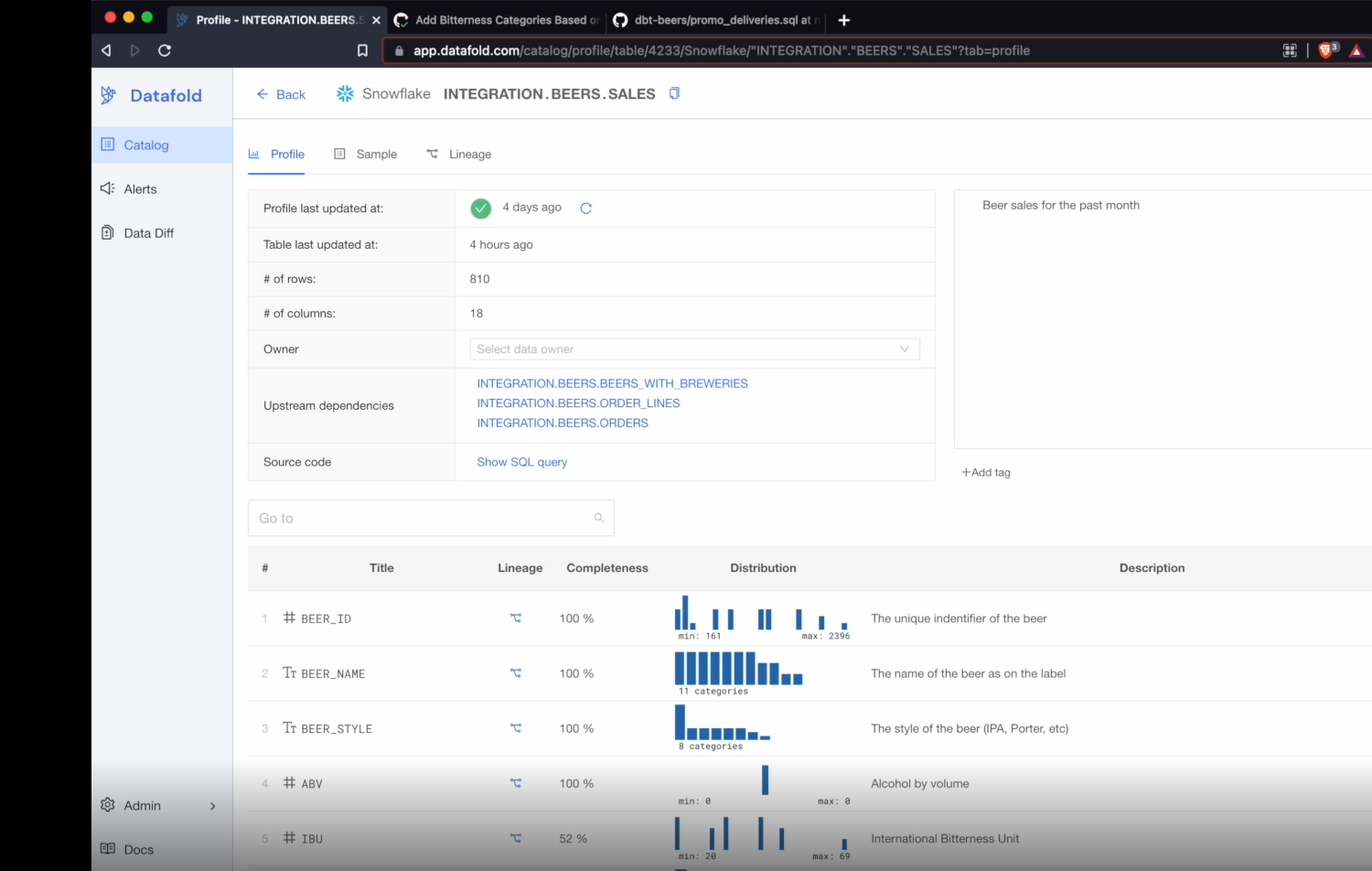
Datafold is a data observability tool that assists data teams in monitoring data quality by utilizing diffs, anomaly detection, and data profiling. Data profiling can be used for data quality assurance and table comparisons between databases or inside a database.
You can also use Datafold’s automatic metrics monitoring module to produce smart alerts from any SQL query with a single click. Data teams use this tool to monitor ETL code changes during data transfers and link them with their CI/CD to quickly examine the code.
10. Collibra

Collibra Data Quality & Observability automates monitoring, validation, and alerting across data sources and throughout data pipelines. Collibra validates data using out-of-the-box criteria, profiling it to understand its structure and content. Rule thresholds may then be adapted and adjusted to changing situations using machine learning, depending on observed data set ranges.
Using generative AI, data teams can convert business rules into specific technical rules without the need for SQL knowledge. You can connect anomalies with changes to find the underlying reason. Collibra can send notifications to stakeholders as soon as issues arise, preventing them from snowballing into big problems.
11. dbt Core

dbt (data build tool) is a popular open-source command-line solution that lets you create, test, and deploy complex data transformations while also performing built-in data quality checks. These tests allow you to ensure the correctness and consistency of your data across the data pipeline.
dbt data quality checks can help you confirm that your data is accurate before utilizing it for downstream analysis. Tests are activities documented in the dbt codebase that verify the data on your data platform.
When a dataset is created in the dbt pipeline, the tool performs an audit and determines whether to build the next dataset depending on the test results (pass, fail, or warn). If a check fails, you may tell dbt to deliver a warning and continue generating downstream models, or you can indicate that the process should end and report an exception.
12. Soda Core

Soda Core is an open-source command-line program and Python library that uses the Soda Checks Language to convert user-defined data into aggregated SQL queries. When Soda Core scans a dataset, it performs checks to identify incorrect, missing, or unexpected data. When Soda Checks fail, they reveal low-quality data.
Soda Checks are defined in YAML format and serve as the foundation for validation (Soda Scans). With alert levels and fail conditions, SodaCL provides extra options for creating more complicated anomaly handling systems. Soda also provides various integration options, including Snowflake, BigQuery, and Redshift, and relational database systems, including PostgreSQL, MySQL, and Microsoft SQL Server.
The Importance of Using Data Quality Management Tools
Data quality tools help teams make data more trustworthy and manageable. Inaccurate data leads to bad decisions, missed opportunities, and lower earnings.
This is why data quality has become a major concern as data sets continue to expand and become more complex.
Each data quality tool comes with a unique set of features that may fit various use cases. Monitoring capabilities are essential for tracking data quality metrics. When problems are found, they can notify data management teams so that they can investigate them sooner, when they are easier to resolve.
What metrics are we even talking about?
What Data Quality Metrics Should You Track?
Data quality metrics are key for evaluating and assessing the data quality within a company.
First of all, you have the standard data quality dimensions:
| Data Quality Dimension | Description |
|---|---|
| Timeliness | Data’s readiness within a certain time frame. |
| Completeness | The amount of usable or complete data, representative of a typical data sample. |
| Accuracy | Accurate and reliable data based on the agreed-upon source of truth. |
| Validity | Checks how much data conforms to the acceptable format for any business rules. |
| Consistency | Compares data records from two different datasets. |
| Uniqueness | Tracks the volume of duplicate data in a dataset. |
For each of those dimensions such as data accuracy, you can find some relevant metrics:
Data to Errors Ratio
This metric is very important because it gives you an idea of how many errors you can expect in your data set relative to its size. The metric basically counts known errors in a data set and compares this number to the size of that data set. You need this information to know whether your data quality processes work.
Number of Empty Values
Counting how many times an empty field appears in a data set is a good idea as well. Why are empty fields important if they’re empty? Such fields often reflect information that has been entered incorrectly or may be completely missing. Data management tools should pick up on this type of information.
Data Time-to-Value
Another key point: it pays to check how much time it takes your team to extract relevant insights from data. If it takes longer than you thought, at least you’ll have a solid data point to rely on when asking for data quality management tooling.
Data Transformation Error Rate
This metric tracks the frequency with which data transformation activities fail. If you notice this rate going up, you’ll know that it’s time to act now before the issue snowballs into a massive problem.
Timeliness
This metric tracks all the instances when data isn’t available to users when they need it.
| Data quality metric you should track | What it’s all about |
|---|---|
| Data to Errors Ratio | Counts known errors in a data set and compares them to the size of the data set. |
| Number of Empty Values | Counts how many times an empty field appears in a data set. |
| Data Time-to-Value | Evaluates the amount of time it takes to derive relevant insights from data. |
| Data Transformation Error Rate | Indicates the frequency with which data transformation activities fail. |
| Timeliness (SLA) | Tracks when data is not available to users when they require it. |
Benefits of Using Data Quality Tools
Using data quality tools will assist you in better managing and using data. Here are ten key ways data quality technologies can help your organization.
1. Increases trust in your data
Using a data quality tool increases consumer trust in the data. They’re aware that the data quality tool has eliminated low-quality data, leaving only high-quality data on board – enabling truly data-driven decision-making.
2. Enhances decision-making
Incomplete or inaccurate data can lead to erroneous decisions that can have disastrous consequences for the company’s operations and profitability. The higher the quality of your data, the better your decisions.
3. Promotes internal consistency
Poor-quality data might lead to inconsistencies in your organization’s operations, leading individuals and teams to draw various conclusions from different data sets. When everyone across the company uses the same high-quality data, operations, and decision-making become more consistent across departments and regions.
4. Improves agility
Competing in a fast-paced environment necessitates agility. Teams won’t be able to act swiftly if the data is wrong or untrustworthy. Access to more and better data enables you to make faster and more agile decisions.
Consider the effort spent attempting to reach former leads who have relocated or changed email addresses. Working with high-quality, up-to-date data can boost productivity dramatically.
5. Saves time and money
Using data quality technology is less expensive than manual data cleansing. Even more importantly, working with clean data from the start is significantly less expensive than cleaning it later or dealing with the consequences of faulty data.
Remember the ancient adage: It costs one dollar to check data, ten dollars to clean it after the fact, and one hundred dollars to do nothing and bear the repercussions of faulty data.
Up to 80% of data practitioners’ time is spent clearing up poor data. Using a data quality solution removes manual effort and saves a tremendous amount of valuable time, allowing team members to focus on other productive tasks.
6. Enhances regulatory compliance
Every company must follow some type of industry standards. If your data processes are questionable, you may jeopardize your customers’ privacy. Working with higher-quality data helps ensure compliance and avoid harsh financial penalties easier.

Expert Tip: Prevent Data Quality Incidents by Branching Early in Pipeline Development



Oz Katz is the CTO and Co-founder of lakeFS, an open source platform that delivers resilience and manageability to object-storage based data lakes. Oz engineered and maintained petabyte-scale data infrastructure at analytics giant SmilarWeb, which he joined after the acquisition of Swayy.
Traditional data quality tools alert you after bad data reaches production (e.g. dashboards break, reports show anomalies, etc.). For enterprises managing petabyte-scale data pipelines, this reactive approach can cost millions in lost productivity, missed SLAs and downstream preprocessing.
By adopting a proactive approach, you can prevent impact before it reaches production. This comes in the form of:
- Creating isolated branches for each transformation, schema change, or new data ingestion before touching production. Run your entire quality validation suite against branch data without risk.
- Integrate quality gates with your existing tools. Pair Great Expectations, Soda Core, or dbt tests with lakeFS branches. Only merge to production after validation tests pass – bad data never reaches consumers.
- Automate with CI/CD (Write-Audit-Publish Patterns) and orchestration. Configure Airflow, Dagster, etc. to automatically run quality checks on branches and merge only after all gates pass. Failed checks? The branch is discarded and production remains unharmed.
- Reduce MTTR. Instead of debugging production data and reprocessing terabytes , identify issues in isolation, fix them on a branch, and promote only validated data.
What Features to Look for in a Data Quality Tool?
When assessing different data quality tools, you might get dizzy by the sheer scale of features on offer. But data quality boils down to a few essentials. Here are the essential features your data quality tool should have:
- Data Profiling -A good solution should have strong data profiling features that allow users to explore and analyze their data, find trends and anomalies, and evaluate the quality of their data assets.
- Data Cleansing – A data quality tool should include full data cleansing capabilities, such as validation, standardization, deduplication, and enrichment. These should be adaptable and configurable, allowing users to create their own data quality standards and criteria while also automating the cleansing process to guarantee data quality remains consistent over time.
- Data Monitoring and Validation – Your tool of choice should include tools for tracking data quality metrics and indicators, notifying users of possible problems, and verifying data against established rules and criteria. These should be flexible and adaptable, allowing businesses to set their own data quality standards, warnings, and validation procedures depending on their own needs and requirements.
- Error Detection and Root Cause Analysis – Make sure the solution you pick includes error detection tools, allowing users to identify data quality concerns and their origins. It should also provide root cause analysis capabilities, allowing users to explore and comprehend the underlying issues causing data quality concerns.
- Integration with Data Pipeline Tools – A data quality platform should be able to work smoothly with other data management tools and systems, such as data integration, business intelligence, and analytics software. Look for one that includes pre-built connectors, APIs, and other integration options to ensure seamless interaction with your current data management environment.
How to Choose the Right Data Quality Tool for Your Business
What’s the best data quality tool for your use case? Choosing the right data quality tool may appear daunting, but it’s worthwhile to invest time to study and pick the best tool for the job. Here are a few factors to consider:
- Your use case and data quality requirements – What are the data quality requirements of the business?
- Price – Is the tool based on a subscription fee or a one-time fee? Are there any add-ons that will increase the price?
- Data integration – How easy can you integrate data, if this use case is important to you?
- Usability and experience – Is it easy to use? Will it do all of the required tasks?
- Support – How much assistance will you need? The availability of live help from the tool vendor could be a deciding factor. Large enterprises will typically require a team dedicated to assuring data quality, so support is critical.
Conclusion
As cloud complexity grows, data quality control becomes increasingly important. You must be able to successfully clean, manage, and analyze data from a variety of sources, including social media, logs, IoT, email, and databases.
This is where data quality tools come in handy. They can fix data in the event of formatting problems, typos, and so on, as well as remove unneeded data. These can also be used to apply rules, eliminate costly data discrepancies, and automate operations in order to boost your company’s income and productivity.
If you’re looking for an in-depth guide with practical steps towards data quality, check out this one: How to maintain data quality with data versioning.
Frequently Asked Questions
At enterprise scale, data quality shifts from static rules to continuous observability, automated detection, and system-wide visibility.
- Deploy observability platforms (Monte Carlo, Bigeye, Anomalo, Lightup) to detect anomalies without manually defining every rule.
- Correlate quality issues with upstream pipeline changes using lineage-aware root cause analysis.
- Monitor SLAs for freshness and timeliness, not just correctness.
- Measure transformation error rates to detect fragile pipelines before downstream impact.
Learn how to debug and reproduce data pipeline issues with Apache Airflow.
The best tools for ML data quality focus on validating training data, monitoring drift, and making datasets reproducible across experiments and production runs.
- Use lakeFS to version raw data, feature sets, and curated training datasets. When model performance degrades, instantly rollback to the exact data version that produced good results. Reproduce any historical training run by checking out the specific data commit.
- Use Great Expectations or Soda to define data quality rules (schema, ranges, nulls, distributions) and fail training jobs when expectations aren’t met.
- Use Evidently or WhyLabs to detect data drift, feature distribution changes, and label skew between training and production.
- Use TensorFlow Data Validation (TFDV) when working in TensorFlow pipelines to automatically infer schemas and catch anomalies in features.
- Use feature stores (Feast, Tecton) to centralize feature definitions and prevent training/serving skew.
Discover how to improve ML pipeline development with reproducibility.
The best data transformation tools depend on your scale, team skills, and where transformations run but modern stacks usually combine SQL-first tools with scalable engines.
- Use dbt for analytics engineering and SQL transformations when your data lives in warehouses or lakehouses (define models as SQL, version them in Git, add tests, and run them in CI).
- Use Apache Spark (PySpark / Spark SQL) for large-scale batch transformations, complex joins, or ML feature engineering that exceed single-node limits.
- Use DuckDB or pandas for local and lightweight transforms during development, prototyping, or small/medium datasets.
- Use streaming tools like Apache Flink or Kafka Streams when transformations must happen continuously on event data.
- Pair transformation tools with data versioning (e.g., lakeFS) to run transforms on isolated branches, validate outputs, and promote only verified results to production.
Learn the benefits of using lakeFS with dbt in modern data stacks.
Leading data observability tools monitor data freshness, volume, distribution, and schema changes to detect pipeline issues before they impact downstream users.
- Use Monte Carlo for end-to-end data reliability, including freshness SLAs, anomaly detection, and incident root-cause analysis.
- Use Bigeye when you want rule-based and ML-driven data quality checks tightly integrated with warehouses like Snowflake and BigQuery.
- Use Databand (IBM) to track pipeline health, job performance, and upstream/downstream impacts across Airflow and Spark.
- Use open-source tools like Great Expectations or Soda to define explicit data quality checks as code and run them in CI/CD.
- Combine observability with data versioning (lakeFS) so alerts can be tied to specific data commits, enabling fast rollback, reproducibility, and safe reprocessing.
lakeFS provides the data version control layer that transforms data quality from reactive detection to proactive prevention through isolated, immutable data snapshots.
- Create a branch before ingestion or transformation to test data quality without affecting consumers.
- Run validation and observability tools against the branch and fail fast on bad data.
- Merge only validated data into production, preventing partial or corrupt updates.
- Roll back instantly to a known-good commit when quality issues are detected.
Discover how write-audit-publish works in our guide.
Idan has an extensive background in software and DevOps engineering. He is passionate about tackling real-life coding and system design challenges. As a key contributor, Idan played a significant role in launching, maintaining, and shaping lakeFS Cloud, which is a fully-managed solution offered by lakeFS. In his free time, Idan enjoys playing basketball, hiking in beautiful nature reserves, and scuba diving in coral reefs.
Table of Contents

